近日,我叔为我弟高考志愿填报的事情焦头烂额。(江苏高考志愿填报竟然能多达 40 个了,你敢信!)
我心想,也许可以为他们做点数据分析工作。于是……
设计
高考志愿填报的核心难点,在于学校、专业众多,普通人很难抉择,尤其是中档学生,一本线以上、211 勉强,对于他们来说,可能选得好就是天堂选不好就是地狱(也只是可能,最终还得看自身)。
他正好位于这档。
(不过在日益强大的数据分析工具面前,这个问题变得不再有挑战性,回想起我曾经填志愿时还只能傻傻地拿着一本大书慢慢比对,不得不感叹当年的我还是年轻。)
在母校曹老师的援助下,我很快地拿到了权威的去年志愿数据(来源:江苏省 2021 年普通类本科批次投档线(物理等科目类) - 招考信息),里面有物理学科本科院校志愿最低分的数据情况,长如下:
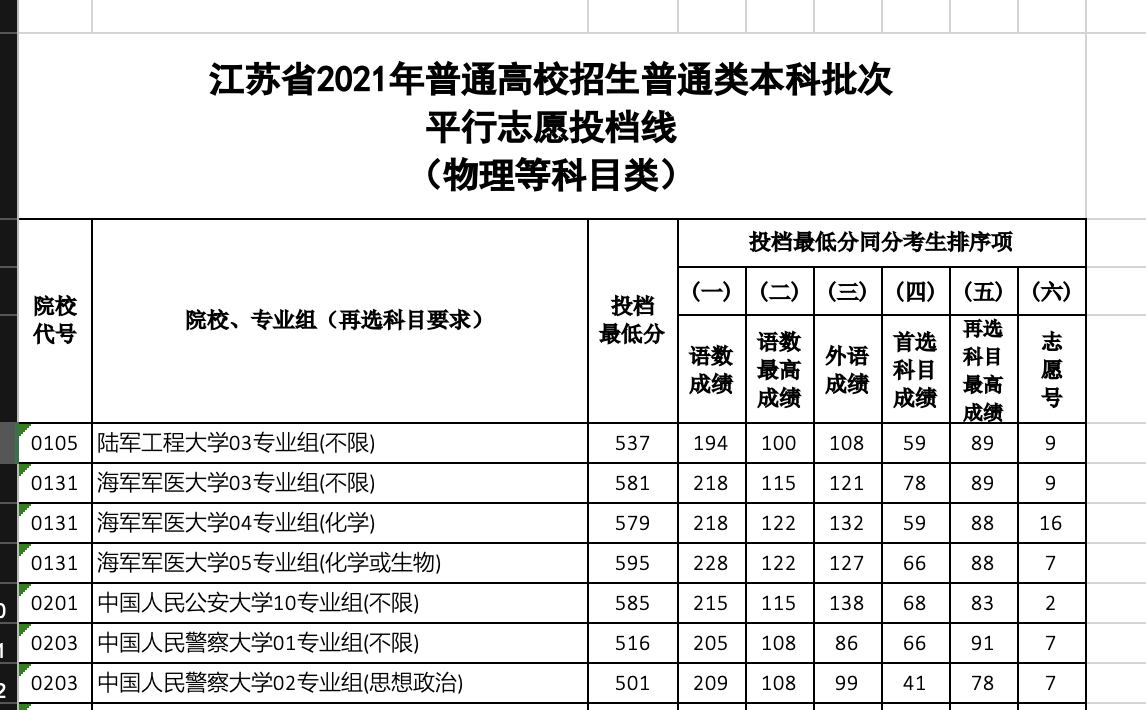
这样,很快地,我们的思路就出来了,只要把我弟的数据录进去,再和这些学校比对,筛选出在他分数上下的院校即可,最好是 985、211、双一流。
因此我们的工作大致有以下几个:
- 清洗这张表格
- 为这张表格加上学校标签标识
- 将分数录入,进行筛选
以下详细展示整个流程。
投档线数据清洗
首先查看表格,是传统的 excel,还有最让编程人员烦的跨行合并的多层标题栏,那么第一步就是重构标题栏。
根据经验,表格的跨行合并,实际上真实数据都在合并的第一行(其他为空),例如取消合并后如下:
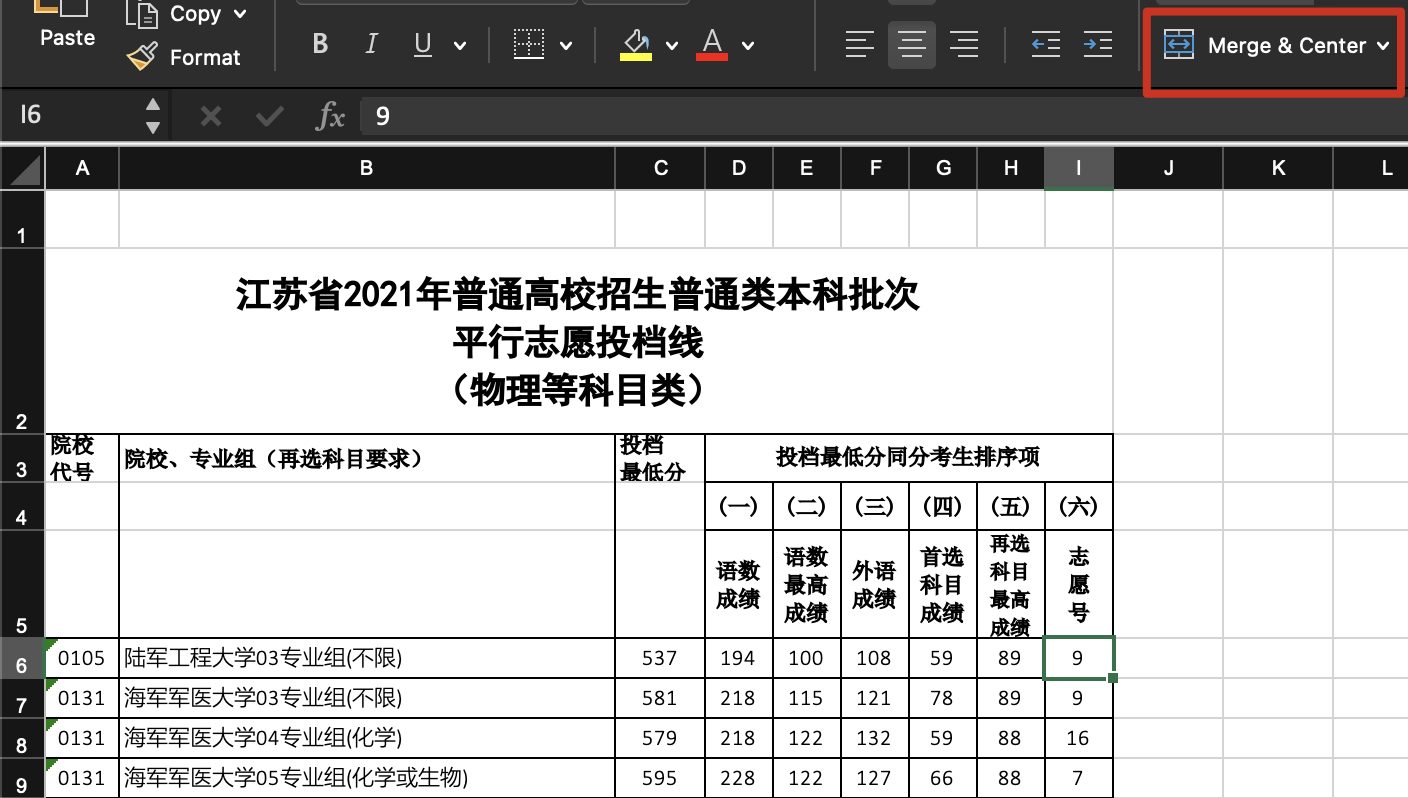
由此可以敏锐地发现,我们只需要把标题栏向下填充,使之全部对齐到第五行,就是可以被程序读取的标题栏了。而这个操作,就是 pandas 内所谓的frontfill(向前填充)。
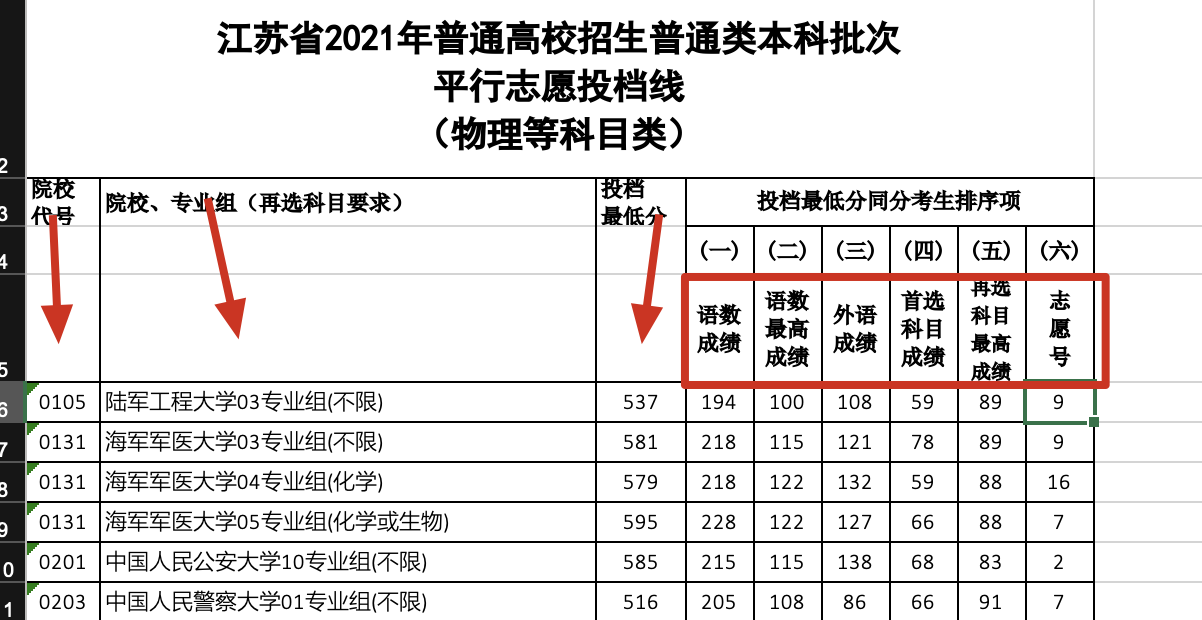
接着标题栏都是中文,并且命名过长,影响编程效率,所以有必要重命名。
此外,接着看内容,“院校、专业组(再选科目要求)”这一列信息量比较大,包含了学校名、专业组和专业限制。
其中专业组是指填报汇总后是根据大专业划分,几个比较近的属于某个专业组,例如计算机、软件、电子信息就很有可能属于同一个专业组,有点类似一级学科的意思,但也不太一样,主要是按招生对象不同,比如说中外合作的就可能在同一专业组,与其他的专业组可能专业内容上倒是相近的。这个就需要那本大书去查,网上还没有太好的信息。
专业限制是江苏专用的一套规则,按照“3+1+2”的要求,学生在语数外之外先要在“物理”和“历史”中首选一门,作为文理划分的依据;接着在剩余的 4 门(历史、政治、地理、生物)中任选两门,专业限制就是针对这两门,在曹老师的指导下我们了解到它分“不限”、“A”、“A 或 B”、“A 和 B”四种可能,分别属于不同的交并补关系(一开始我以为只有“不限”或者“A 或 B”两种可能,导致程序设计缺陷,这是我的疏忽,由于时间关系,没有做好前期统计的工作)。
因此,我们首先要做的就是把这列拆分,尤其对于专业组限制这块,一开始以为只有“或”的关系,我就把它拆成了一个数组,后来发现还有“和”的关系,这么做就不妥了,因此需要保留原字符串,后续以我弟的具体学科使用函数单独处理。
由此写出我们第一段程序,数据已经变成很干净的结构:

考分数据结构设计
为了通用性,我们在设计考分数据结构时,设计的相对比较保守,因为里面存在一些勾稽关系,所以使用@property保证数据的一致性。此外,由于每年分数线差异,因此需要做换算,所以加入了bias乘数。

在bias上,默认是 1 这个很好理解;考虑到我们可能有多次对标不同年份的需求(江苏没有,因为江苏改革目前才是第二年),所以需要不断地调整 bias,因此最好的做法,是调整后再返回类本身,这样可以实现链式操作。

链式操作示范:

我们还在数据分的基础上,加入了排名,不过实际没有用上,因为我们没有投档线对应的排名数据。
以上就是整体的数据结构设计。
考分录入、年份修正、风险偏好
在录入上,直接初始化即可。
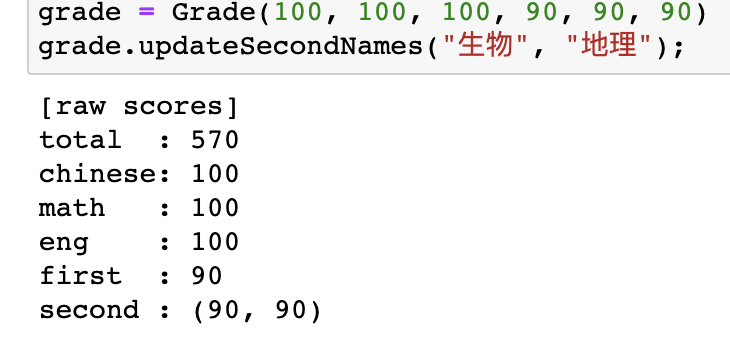
在年份修正上,则有些讲究。它本质的问题是确定,今年的分数在往年值多少分的问题。
我原先想用一本分数线做测度,但是江苏已经取消一本线了,只有本科线(也就是二本线)。
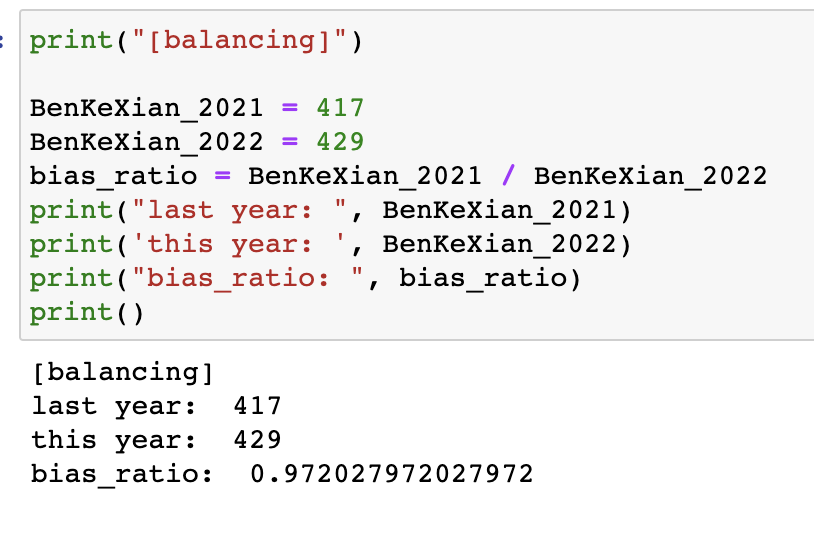
我想了一下,反正这块肯定有误差,在非对标顶级 985 的情况下,直接用二本线比值作为乘数似乎也没什么不妥。
比如去年本科线是 417,今年是 429,比值是 0.97,也就是今年的 1 分等于去年的 0.97 分。
在年份修正的前提下,我们还得考虑一下风险偏好,目前我们看到的都是最低志愿投档线,因此实际已经很有风险,也即是现在看到的贵校的 N 分,实际进入该专业的学生可能都是 N*k 分,k 显著大于 1。
所以正常情况下,我们得在折合分上再乘以一个系数,降低一下自身的体位,可能 0.98 比较合适,但是不排除有些人特别 risky,就想搏一搏,单车变摩托,所以我们在筛选的时候也可以适当调高点范围,这就是风险系数,我把它设置成了最高 1.02,这样能多看十分(基数是五百多)的学校。
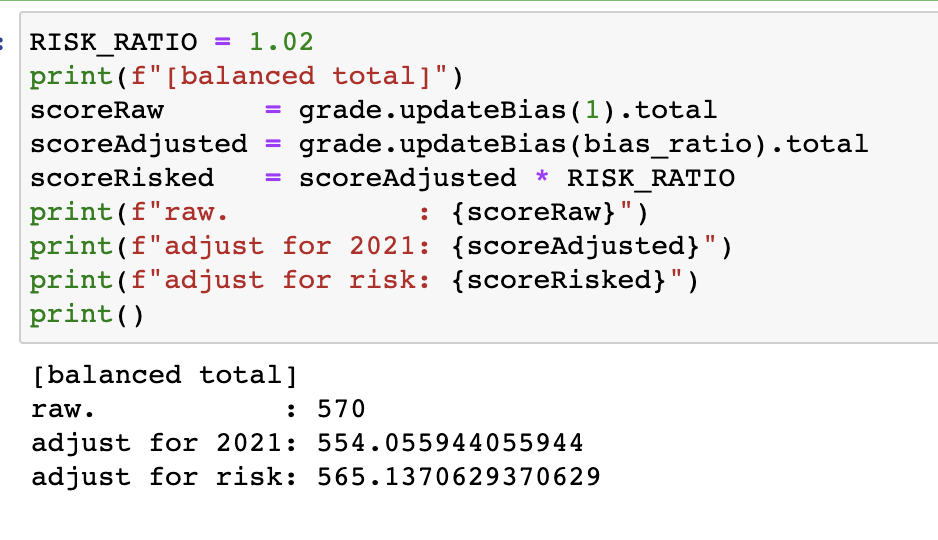
看的时候,以风险调整后的分为最高分,从上往下筛学校即可。
基于学科进行筛选
在学科筛选上,可以写的很复杂,也可以写的很简单。
比较复杂的是一遍遍地 for 循环,然后用 if 去判断,到底符不符合。
我后来想了一种比较简单的,就是用集合的思想去设计。
如果目标专业组要求是“A 和 B”的关系,那么在集合上,我们考生的学科集合(也就是{C, D})应该等于{A, B}。
如果目标专业组要求是“A 或 B”的关系,那么在集合上,我们考生的学科集合(也就是{C, D})应该与{A, B}有交集,也就是 ${C, D} \cap {A, B} \ne \varnothing$。
如果目标专业只有一个,也就是必须要选修它,则是子集关系。
如果目标专业为“不限”,则是恒真关系。
于是,我们可以写成这样:

这样,我们就把 2200 多条筛成了 17000 多条了,减少了 20%,是很不错的。
基于 985、211 筛选
我们首先关注的是 985、211 类大学,看看有没有什么机会。
我们要先拿到一个标签表。
简单搜索后,我们决定使用来自这份博客对照表 - 用心整理了一份国内 985/211 大学名单及其一流学科_黄饱饱_bao 的博客-CSDN 博客的数据。
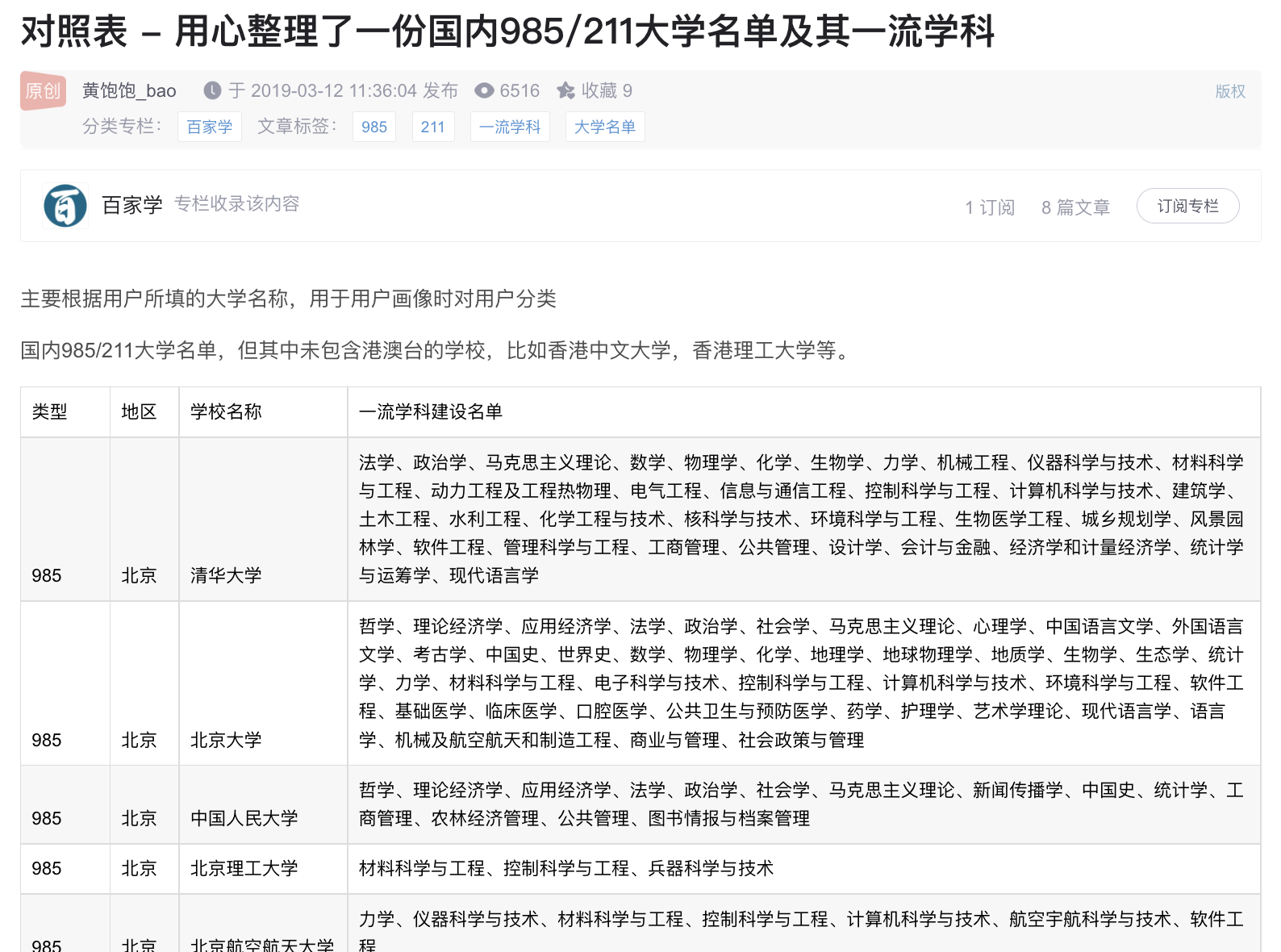
这是一张排版很标准的表格,如果你用 F12 去检查的话确实是标准的table标签。
我们如何把这个数据提取下来呢?
这可是表格,而非文字,直接复制处理起来很麻烦(但有时也未必不可以)。
要用爬虫吗?又觉得杀鸡焉用牛刀。
这时候,我突然想起来很多软件都自带表格数据提取工具,比如 excel 就有网站源数据刷新功能。
重点是,pandas 也不例外!
一行代码,轻松搞定,只要喂一下网址即可!
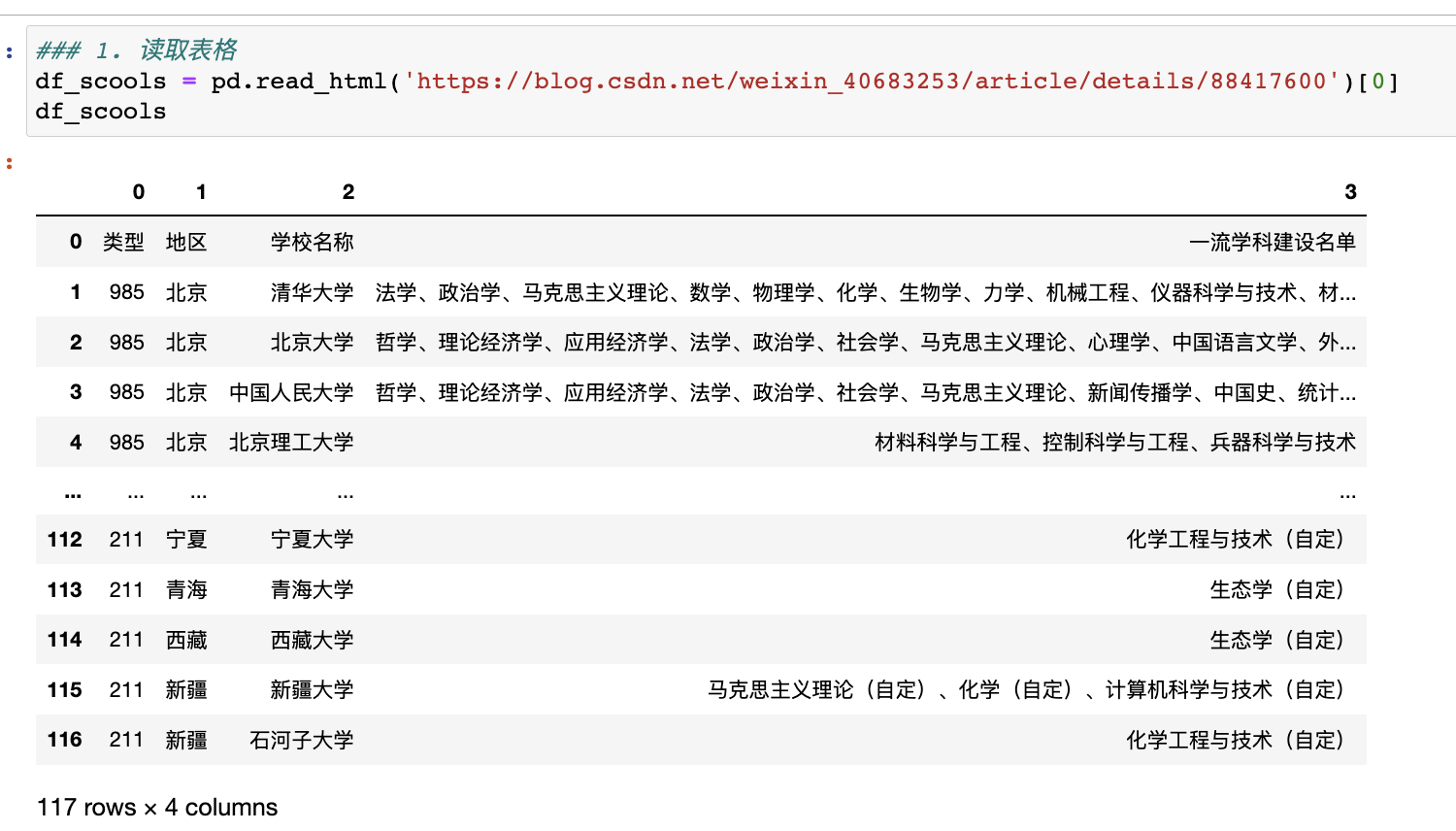
看到这,你是否会很想知道它的内部实现?没错,我也想,有时间再研究研究,估计是requests + beautifulsoup工作流?
简单清洗后,再与原先的那张表做左联操作:
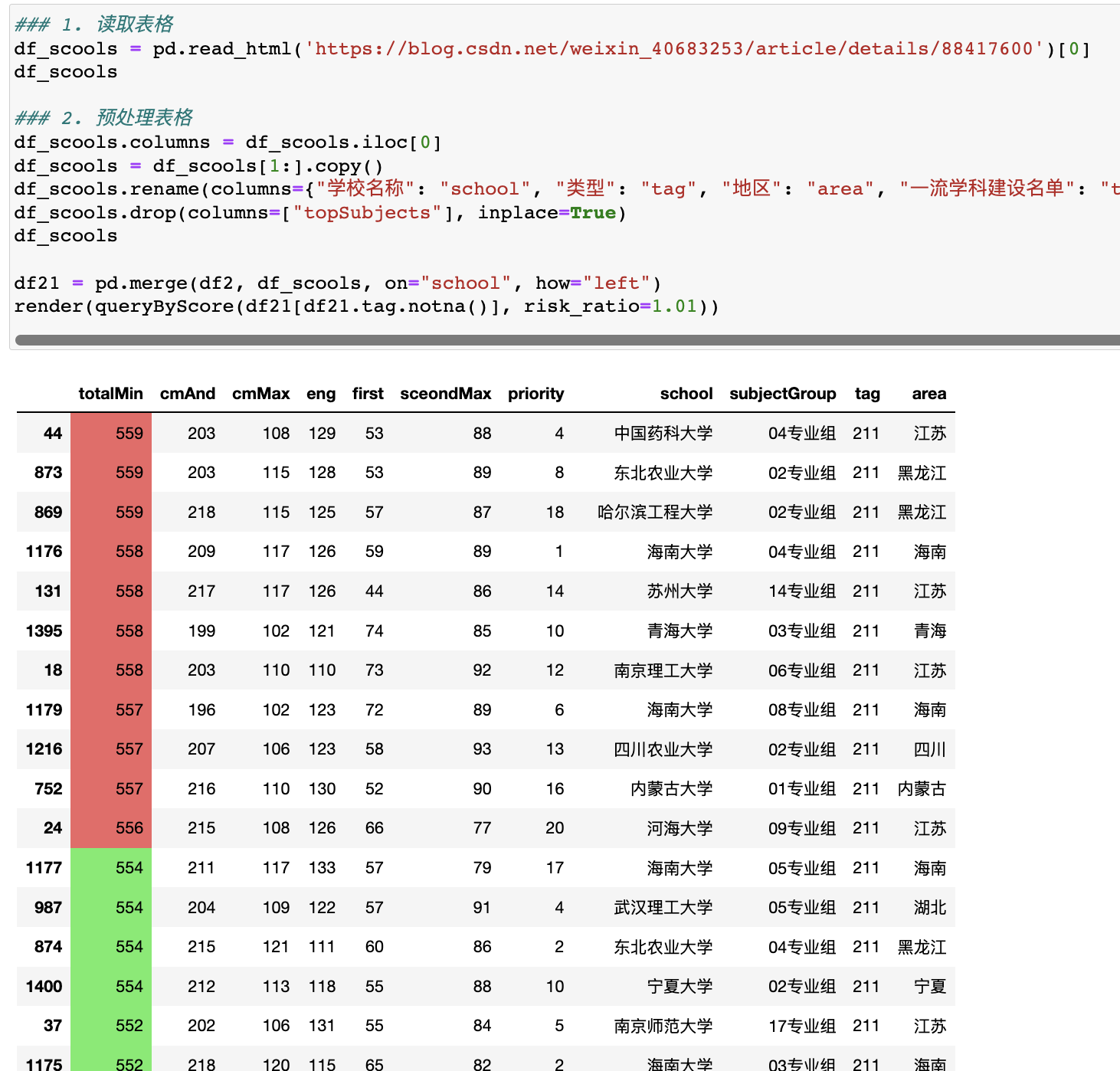
左联操作,就是以左表(投档线表)为基础,加上额外的右表信息(不存在的就是标记缺失)。这个操作,也是数据分析中最常用的。
我们还额外地简单封装了这个染色操作,将不同风险偏好的分数段做染色处理,逻辑如下:

这样风险偏好保守的就看绿色部分就可以,高的可以看看红色(或者作为参考)。
不过很遗憾的是,我弟这个分数 985、211 只能去到很偏远的地方,或者都是中外合作办学项目。
此路似乎不通。
也许我们可以试一试双一流。
基于双一流筛选
我们同样需要双一流的标签数据,之前那个 985/211 的表里虽然也有双一流信息,但是不全,因为有些双非也是有双一流的。
我们在“第一轮双一流”建设高校及建设学科名单_中国教育在线这里找到了我们要的数据。
于是,使用 pandas 梅开二度:

这样就有 140 所学校了,可选性大了些(比 92 多了 20 所左右)。
不过,既然是基于双一流专业,我们肯定更以专业为主(而非学校),所以我们需要额外加一点基于专业的筛选操作。
比如,我们预设几个计算机相关的专业,然后在双一流学科名单中筛选,看看有没有相关的关键字,再结合分数,结果……
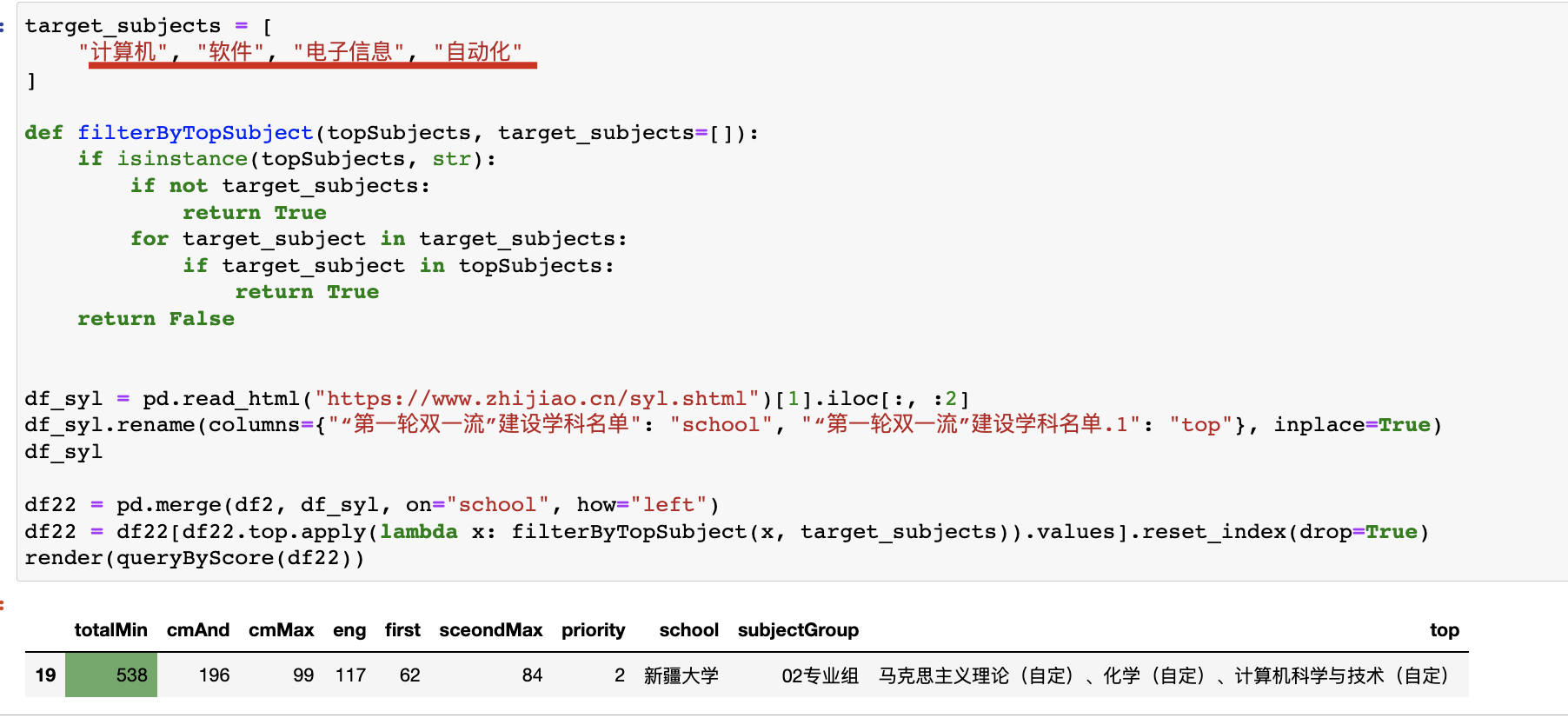
Emmm.....
我陷入了良久的沉思……
既然专业好也可以,那我们为何不试试专业排名(而非紧盯双一流呢?)
这么一想,思路就开阔了,那就是软科排名!
基于软科排名筛选
软科的排名可以在官网找到:权威发布|2022 软科中国大学专业排名|中国大学本科最好专业|就业率最高的专业
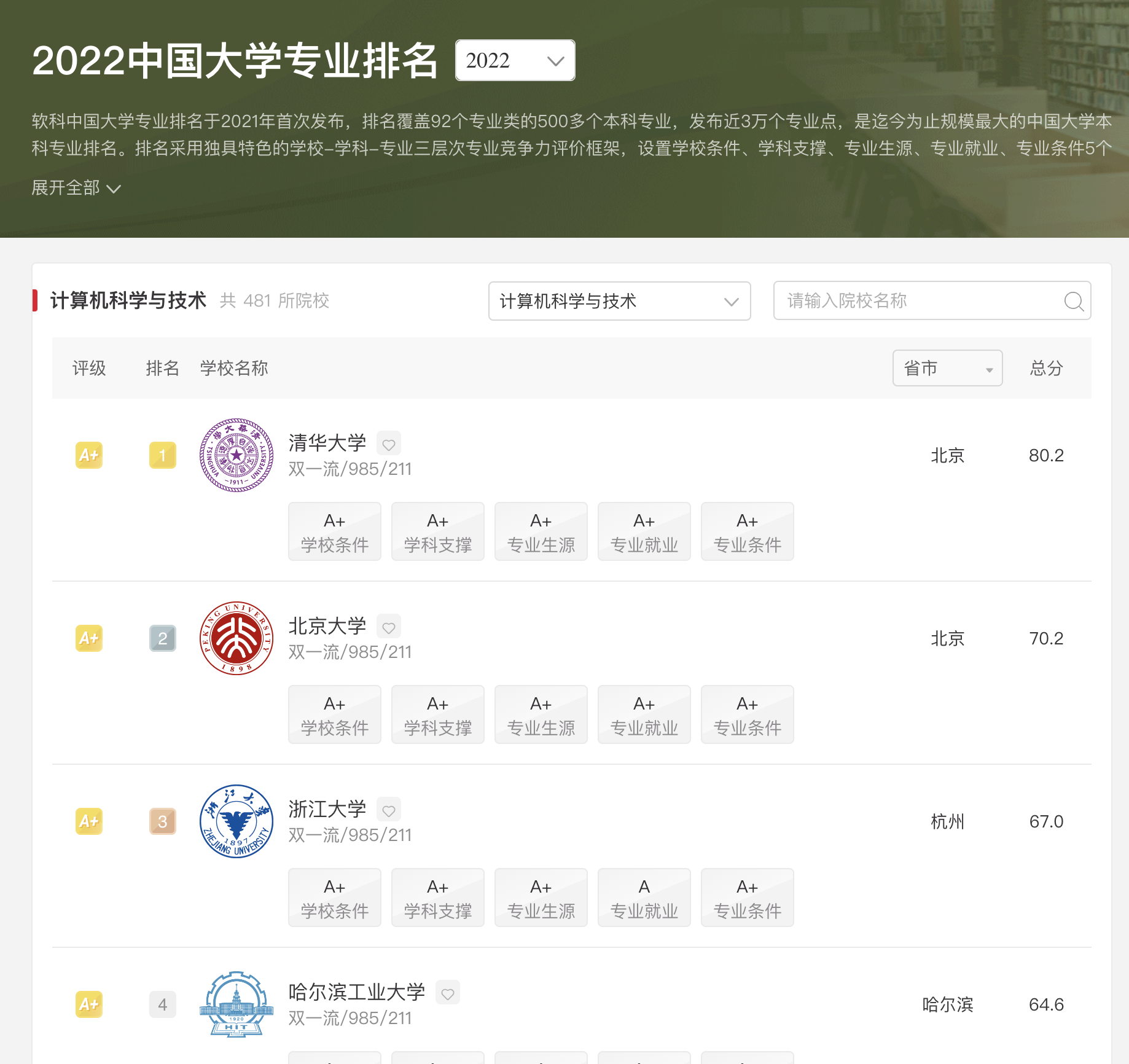
我们可以在这里搜索不同的学科排名。
我们通过 F12 分析后端接口,发现有结构良好的 json 数据:
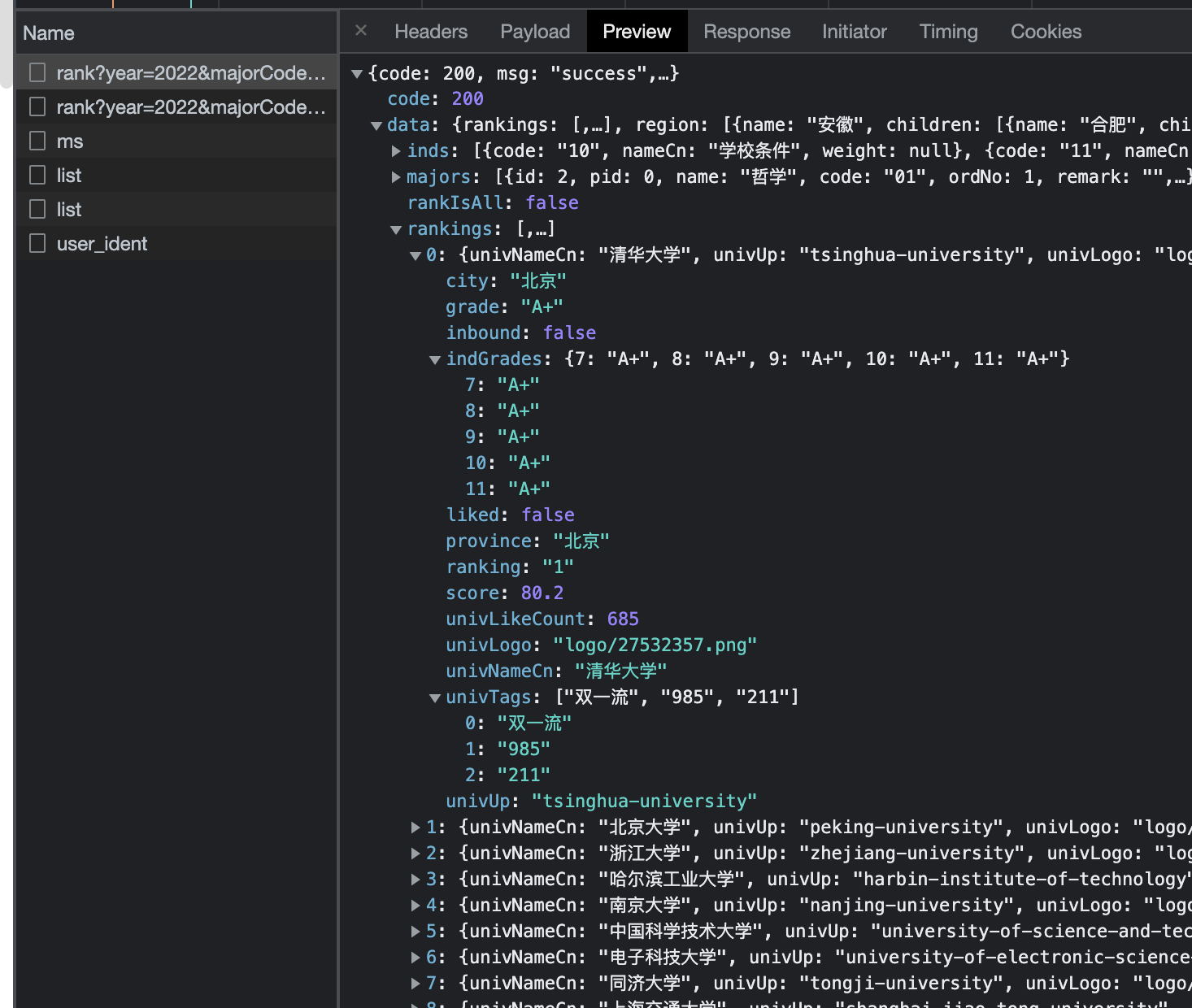
因此,可以考虑直接用爬虫的手段,毕竟每个搜索结果都要翻页十二十次,这显然是必须走自动化了。
经过测试,如果不加 cookie,则获取时只会返回前 20 条,加了 cookie 就可以返回完整结果。
cookie 也就是这个:
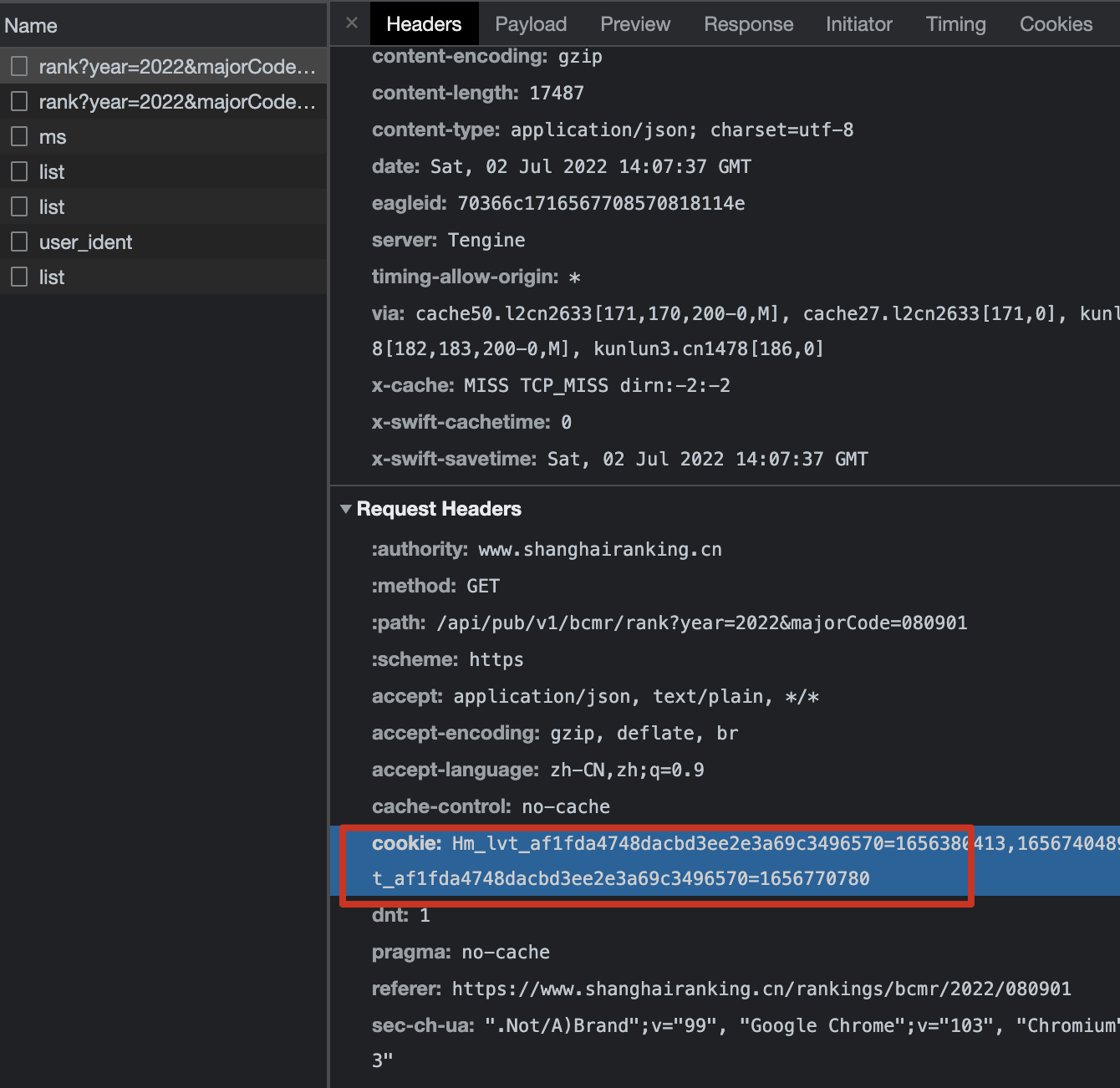
我们把它复制出来,封装一下,就可以设计出得到任意学科的排名数据的接口了:

此外,我们注意到这个接口需要传入学科的编码,因此我们还要设计一个接口获得完整的编码列表。
经过分析,发现任何一个排名接口里已经包含了这份数据(的拷贝),因此我们可以首先调用任意一个专业的排名接口,然后解析出编码列表,代码如下:
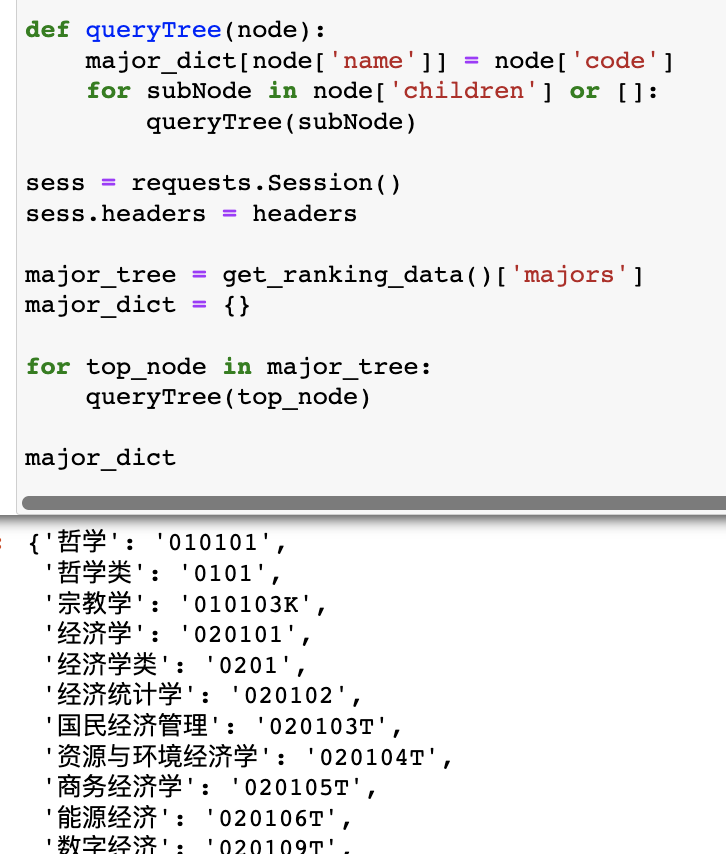
但这只是我们编码好的字典,还不具备输入一个学科名就返回一个学科编号的功能,因此还要封装一个检索函数:

手动修正所有目标专业的准确名称后,我们就可以正式进行分析工作了。
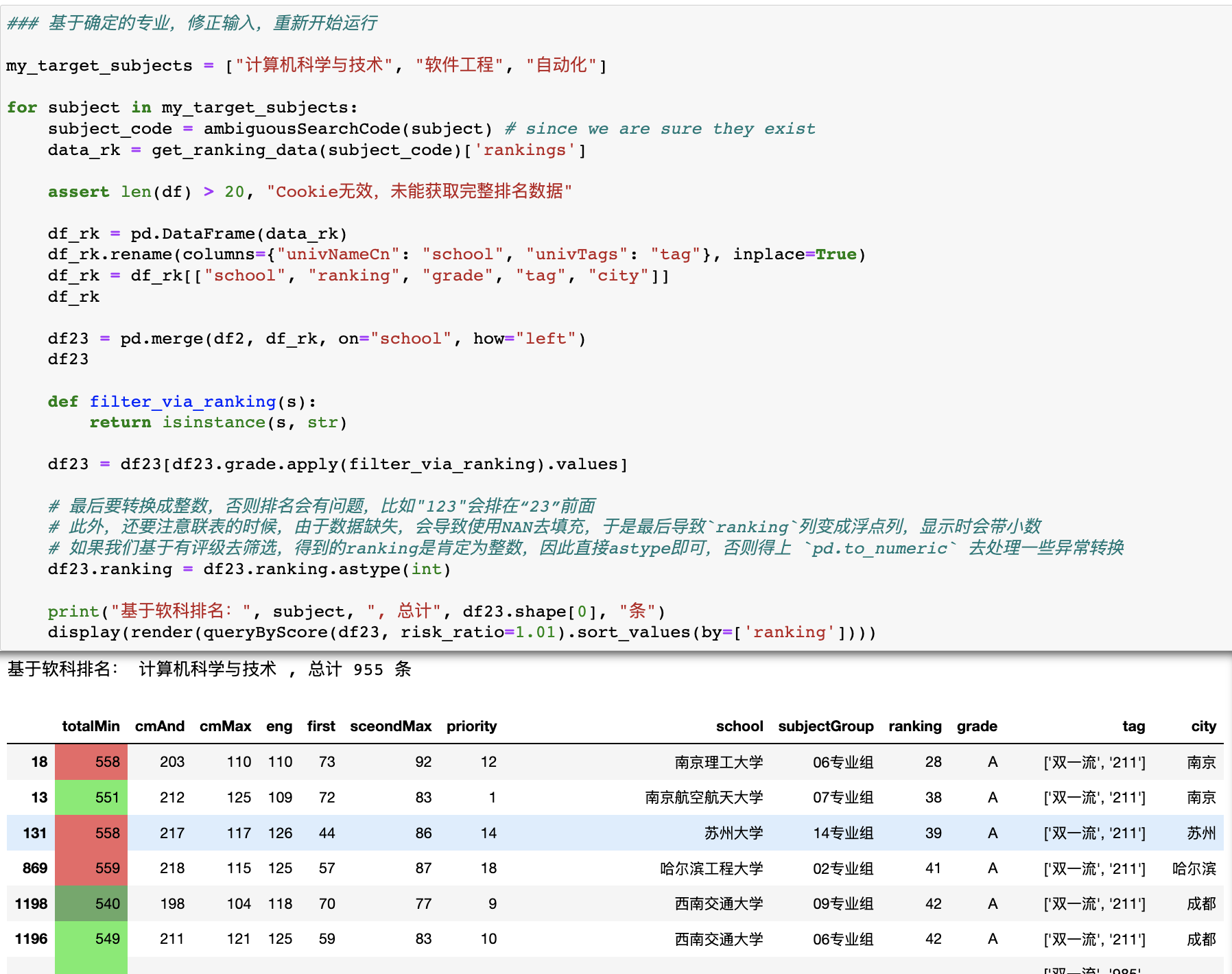
此处唯一多需要注意的是,软科 api 里的ranking是字符串格式的整数,然后到我们 pandas 中也默认是字符串。
如果我们需要对ranking进行排序,就要先转换成整数;但如果我们在联表的的时候没有把非排名院校给筛掉(每份排名名单只有小几百所学校),就会导致数据缺失(变成pd.NaN),从而无法转换成整数,这是需要注意的。
解决办法就是要么直接把那些学校筛掉(比如本例);要么就是使用pd.numeric函数,里面有两个参数errors和downcast可以控制异常如何处理。
技术部分就是这样!
复盘
其实本期最大的收获就是:
对于有 211 分的,直接对照 985、211、双一流名单去选就好了;
对于有一本分的,建议对照软科排名去选
对于其他的……
我今天终于了解到了二本怎么选的了:

哈哈哈,不得不说这是一个很好的思路!
以上!
(全部ipynb程序文件可以后台回复“使用 pandas 研究高考志愿填报”。)
最后感谢我叔提供的素材,以及再次感谢曹老师的热心援助,希望我弟和天下学子最终都能选到心仪的学校,学有所成,不枉此生!