slambook2-ch13
准备
解决编译问题
加载第十三章的 cmake 文件时,第一个问题是关于glog的。
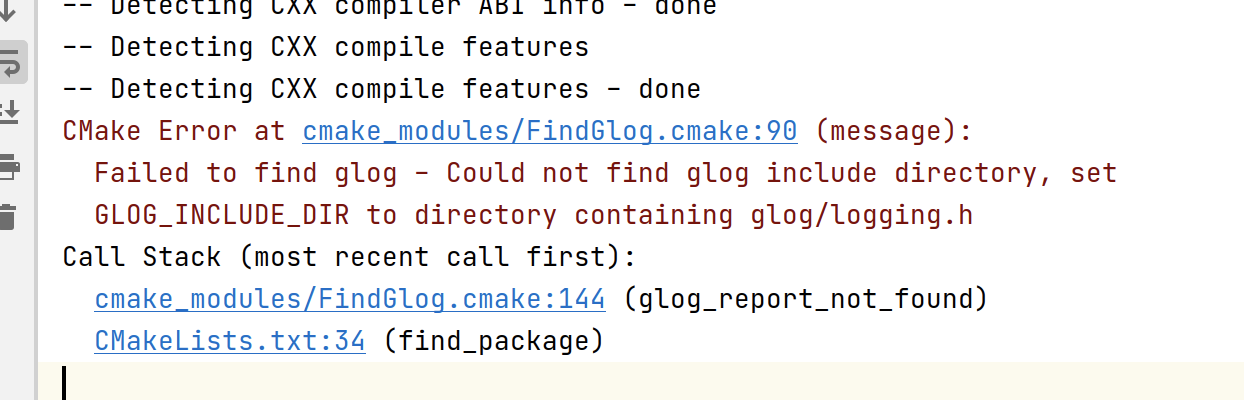
章节里也没提这个,我也不确定在之前的章节里是否有说这个,可能是一个基本工程包,所以我打算手动装一下。
搜索了一下,根据 (5 条消息) Failed to find glog_彩云的笔记的博客-CSDN 博客 指示,只需要 sudo apt-get install libgoogle-glog-dev 即可。
接着重新加载 cmake,问题变成了Could NOT find GTest:
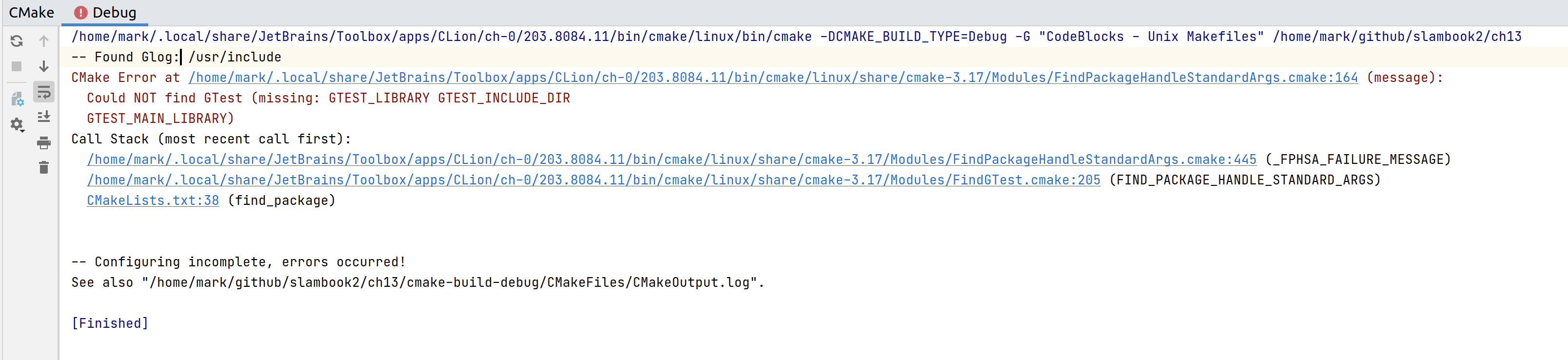
根据 - (5 条消息) 记录 Could NOT find GTest (missing: GTEST_LIBRARY GTEST_MAIN_LIBRARY) 解决方法_Numberors 的博客-CSDN 博客 直接sudo apt-get install libgtest-dev 即可。
接着重新加载 cmake,问题变成了The package name passed to `find_package_handle_standard_args` (CSPARSE) does not match the name of the calling package (CSparse)
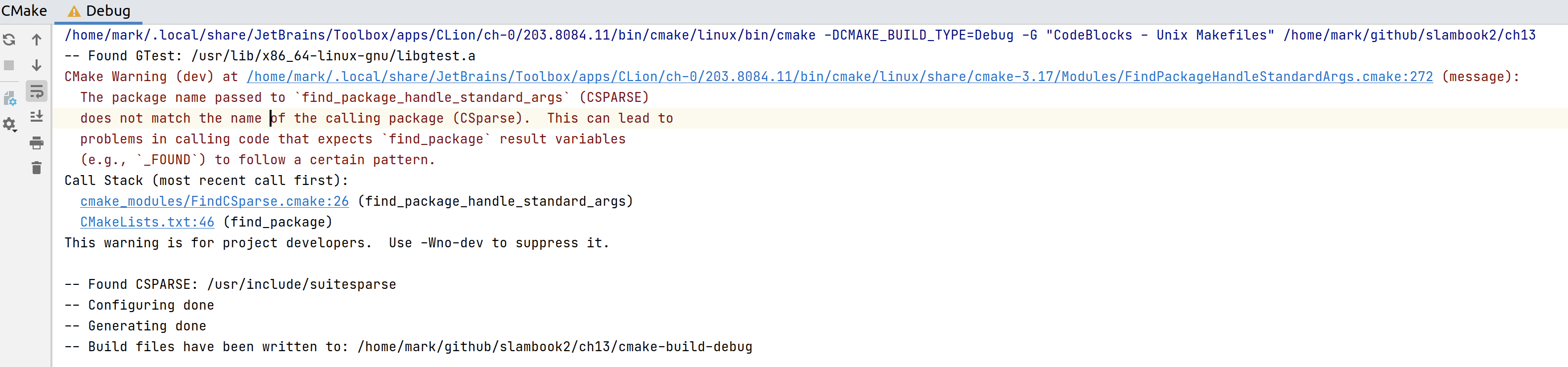
按照 - 【解决问题】【SLAM 十四讲第 7 讲】【关于自己创建工程,遇到的 CSparse 警告的解决方案】 - 代码先锋网 把CSPARSE改成CSParse即可。
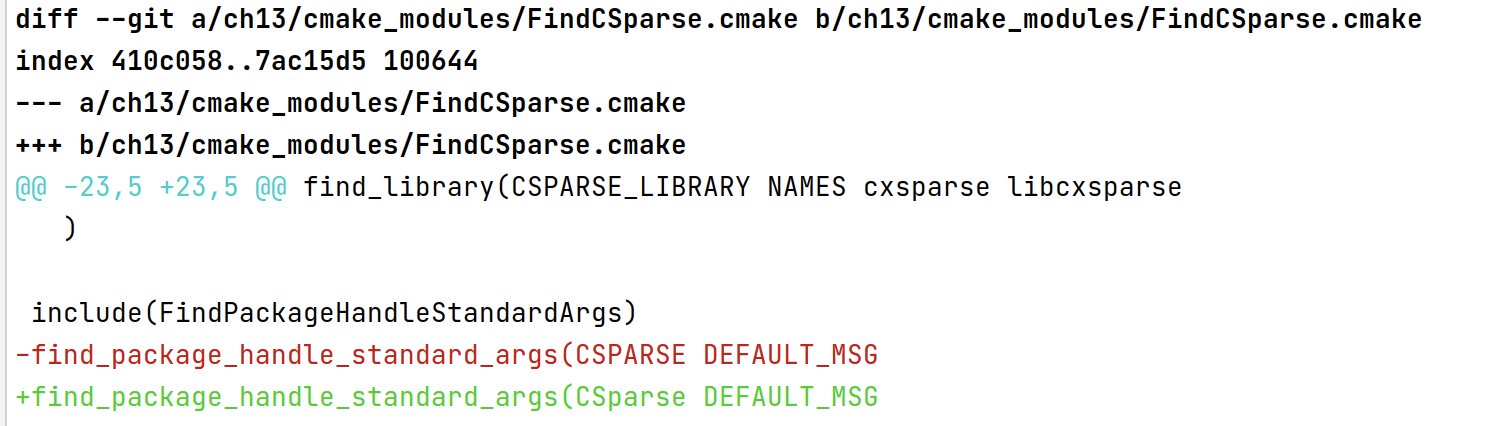
最终,编译成功:
kiti 数据集准备
在之前,我们已经通过迅雷下载完了数据集到 mac 主机上。
接着分别尝试了 smb 和 hgfs 两种方案传输到 ubuntu 虚拟机,smb 受限于带宽只有 20+兆的速度,而 hgfs 逐渐达到了 360+兆。
然后解压,数据集准备完成,并在config/default.yaml中指定数据集位置:
运行run_kitti_stereo
首先遇到的是配置文件不存在的问题,根据经验,应该是 clion 中的 cmake 目录没有配置好:

果然,这里之前写的ch5,修改成 13 再试试看:
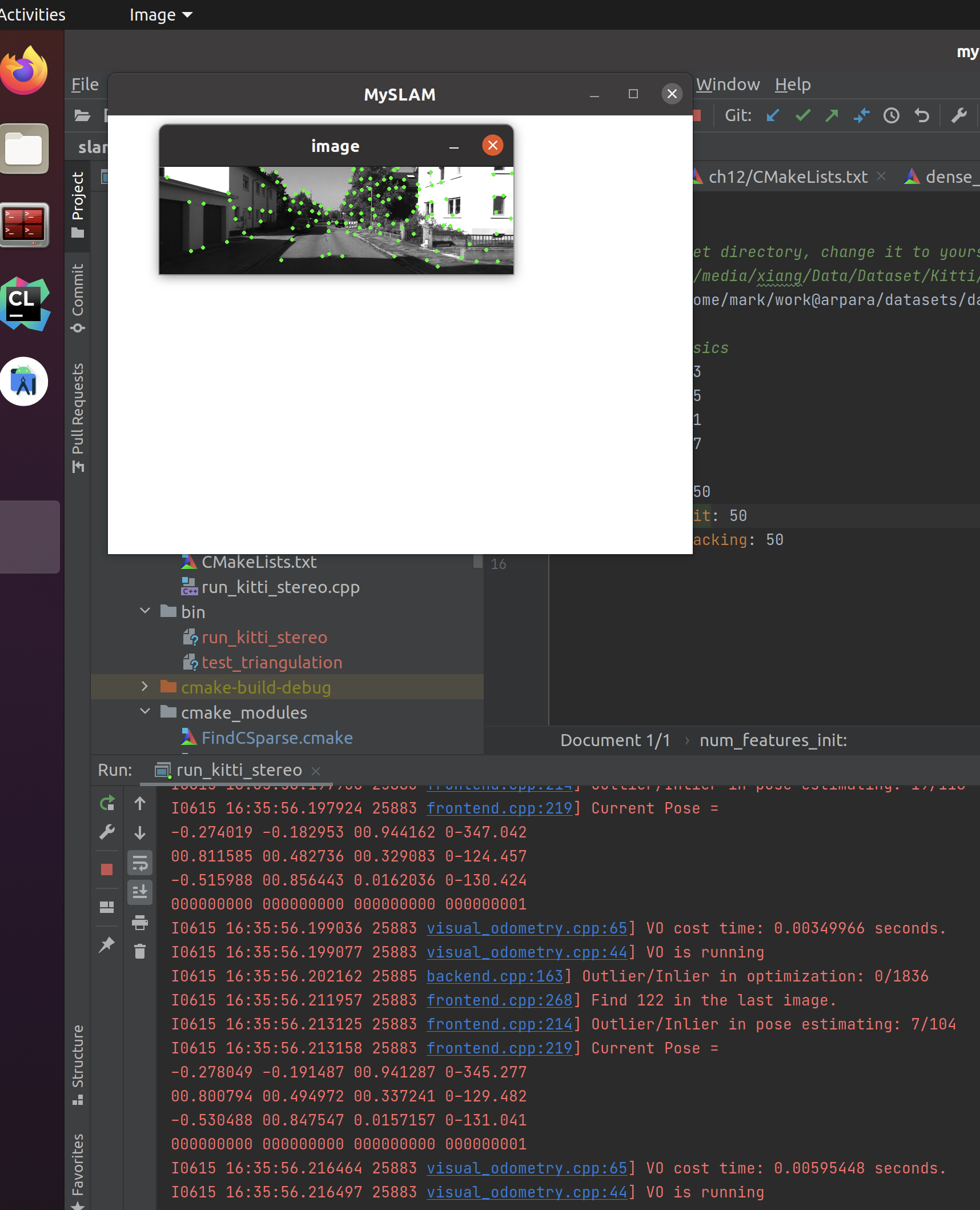
刺激刺激!运行成功了!好酷炫!
理解
run_kitti_stereo.cpp 中 DEFINE_string 和 google::ParseCommandLineFlags 的用意
目前分析来看,DEFINE_String 的主要用途相当于是定义变量+注释。
比如我们直接把那些都去掉,直接传入一个 std::basic_sring<char> & 变量到 myslam::VisualOdometry 函数中,程序也能正常运行。
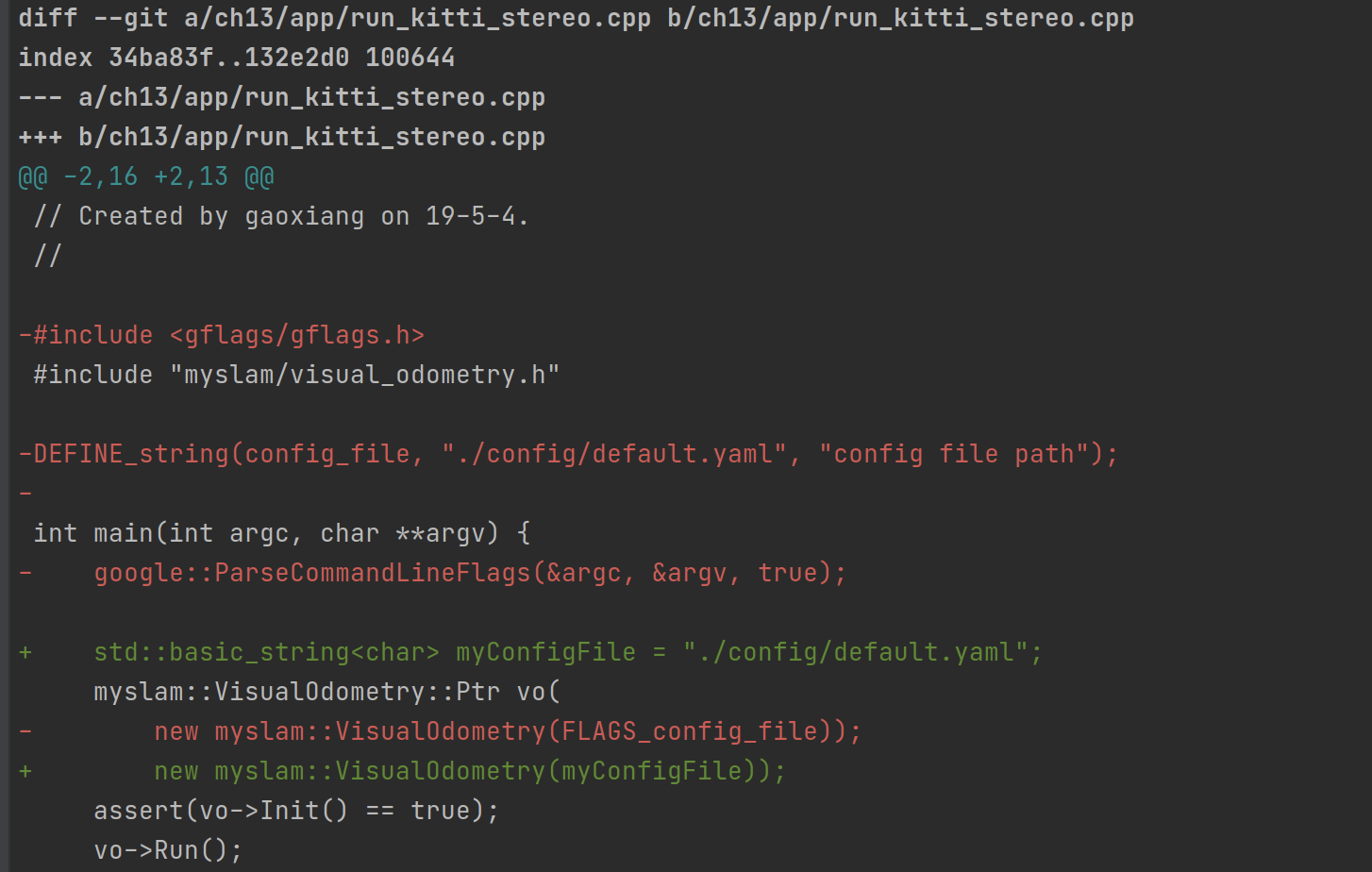
以下是它们两的源代码,附有详细的说明:
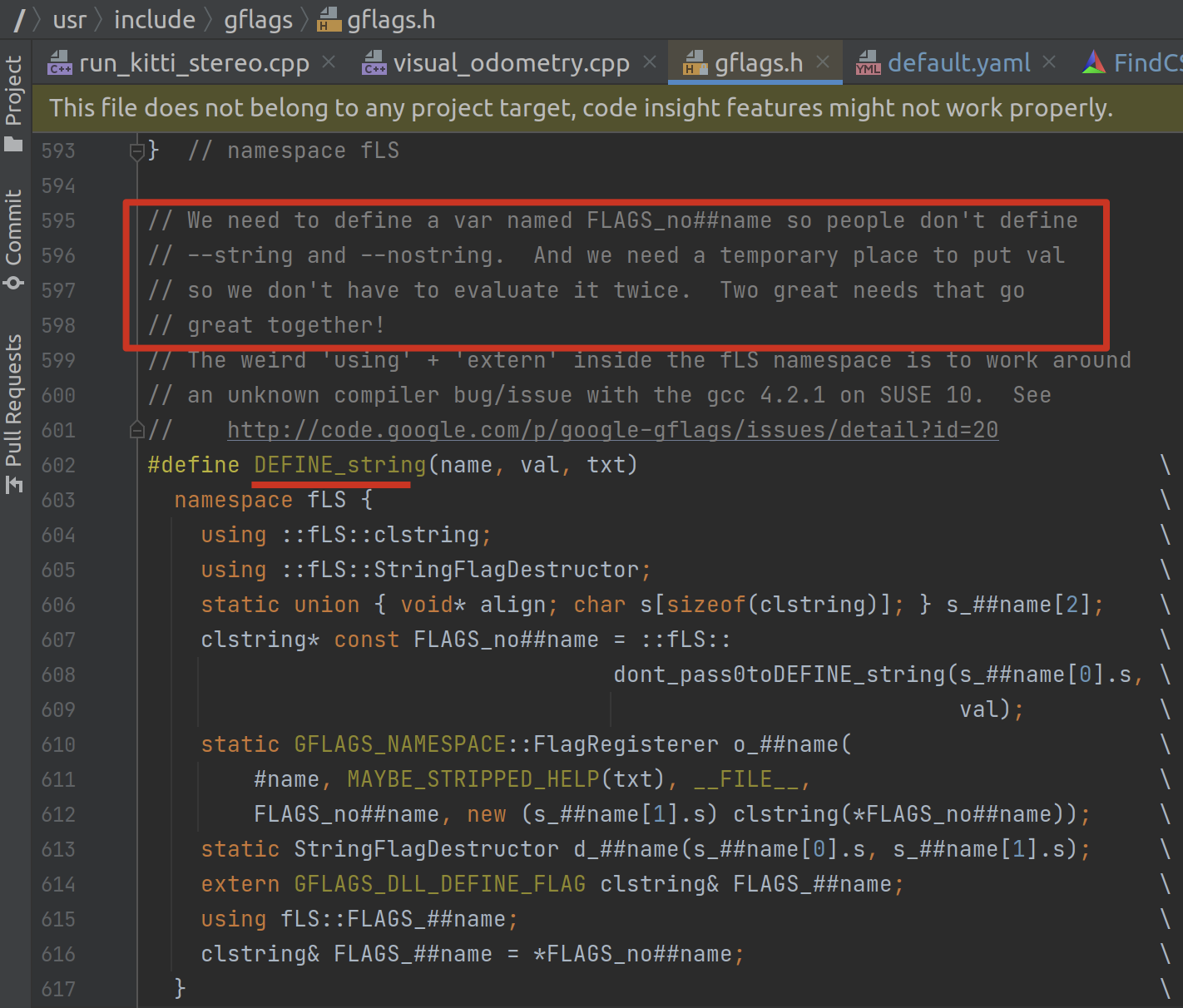
这种写法应该说,比较高级,属于工程级别经验了,比较适合变量很多,尤其是输入参数很多的时候,涉及到系统管理的场景。
读取配置文件的过程
在 myslam::VisualOdometry 的初始化中,将使用 Config::SetParameterFile 去解析文件。
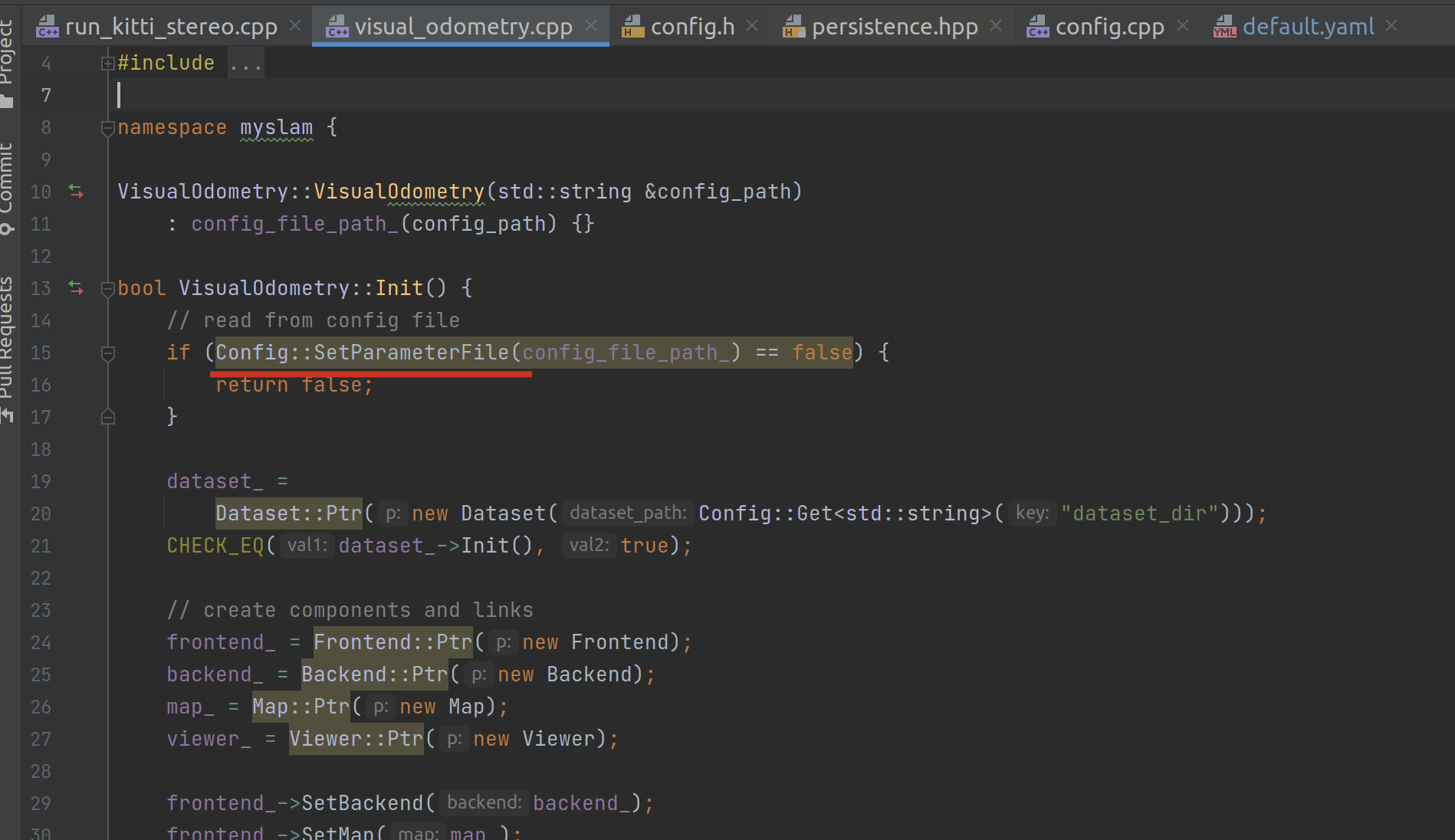
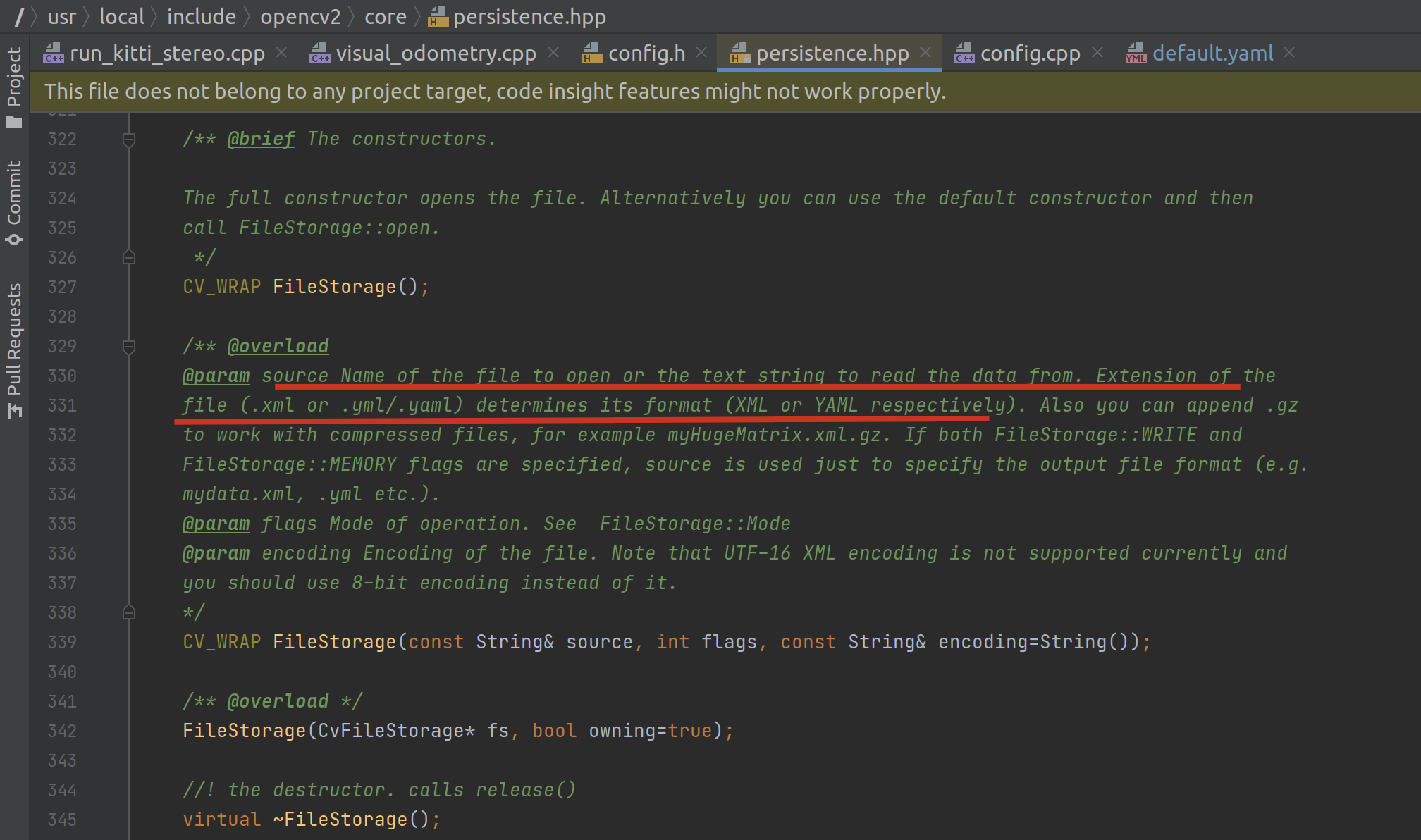
而这个函数其实是调用了 cv::FileStorage 函数:
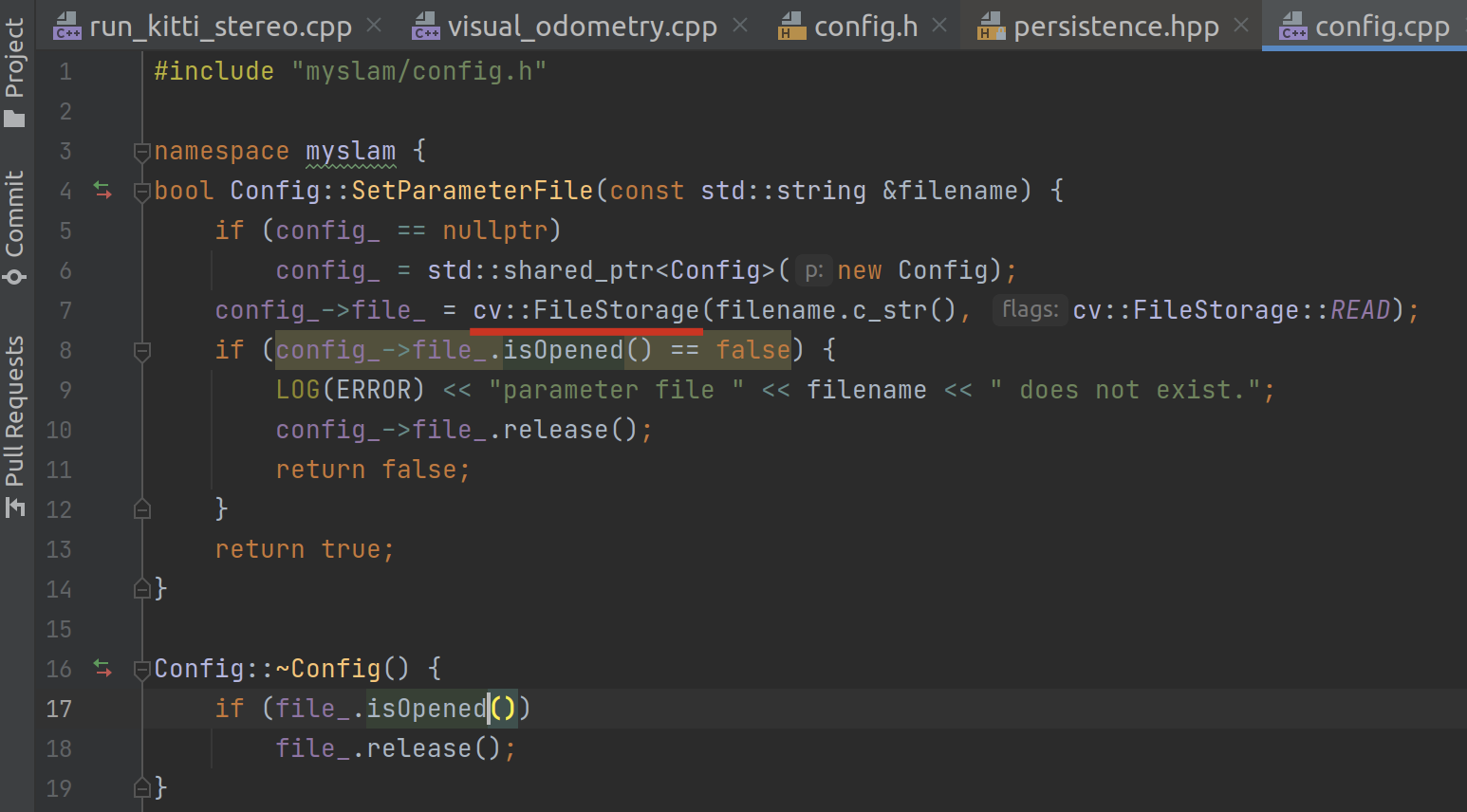
在 cv 的注释中可以看到,它可以读取与解析 xml 或者 yml 格式的文件。
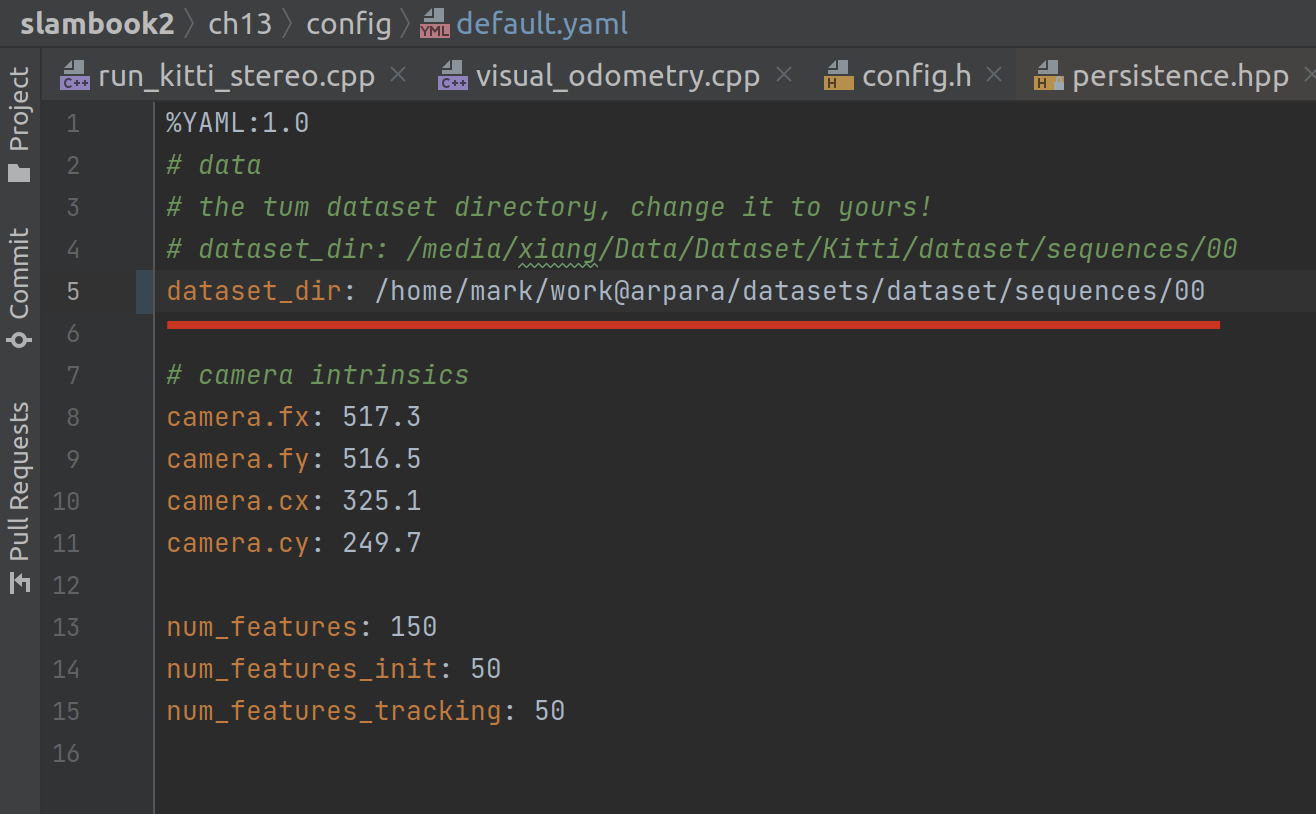
我们的配置文件是一个 yml,里面第一个键就是 dataset_dir:
然后就是调用 Dataset 构造数据集: 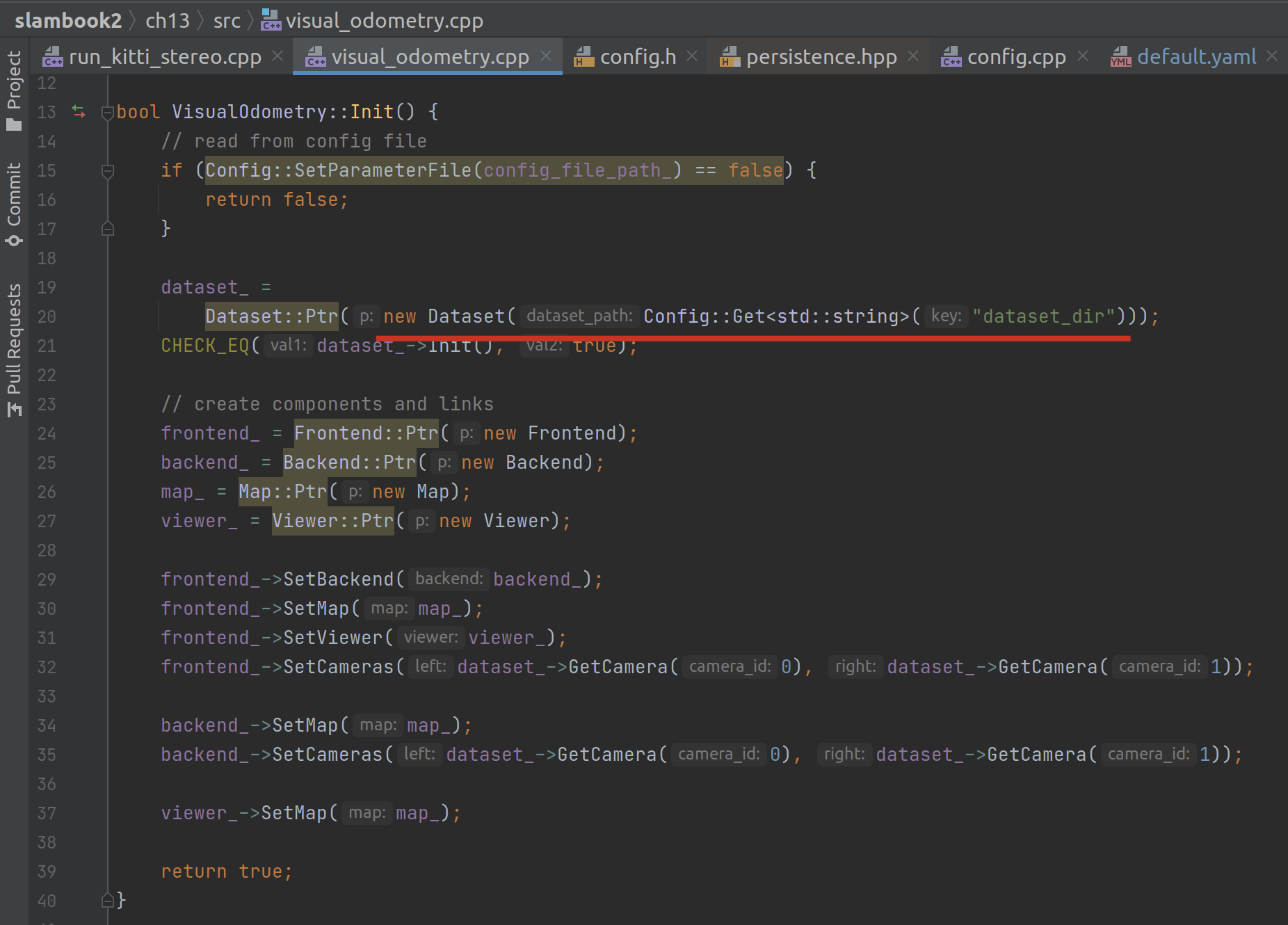
数据集初始化过程
Dataset 初始化的过程中,第一步就是读取数据集里的 calib文件:
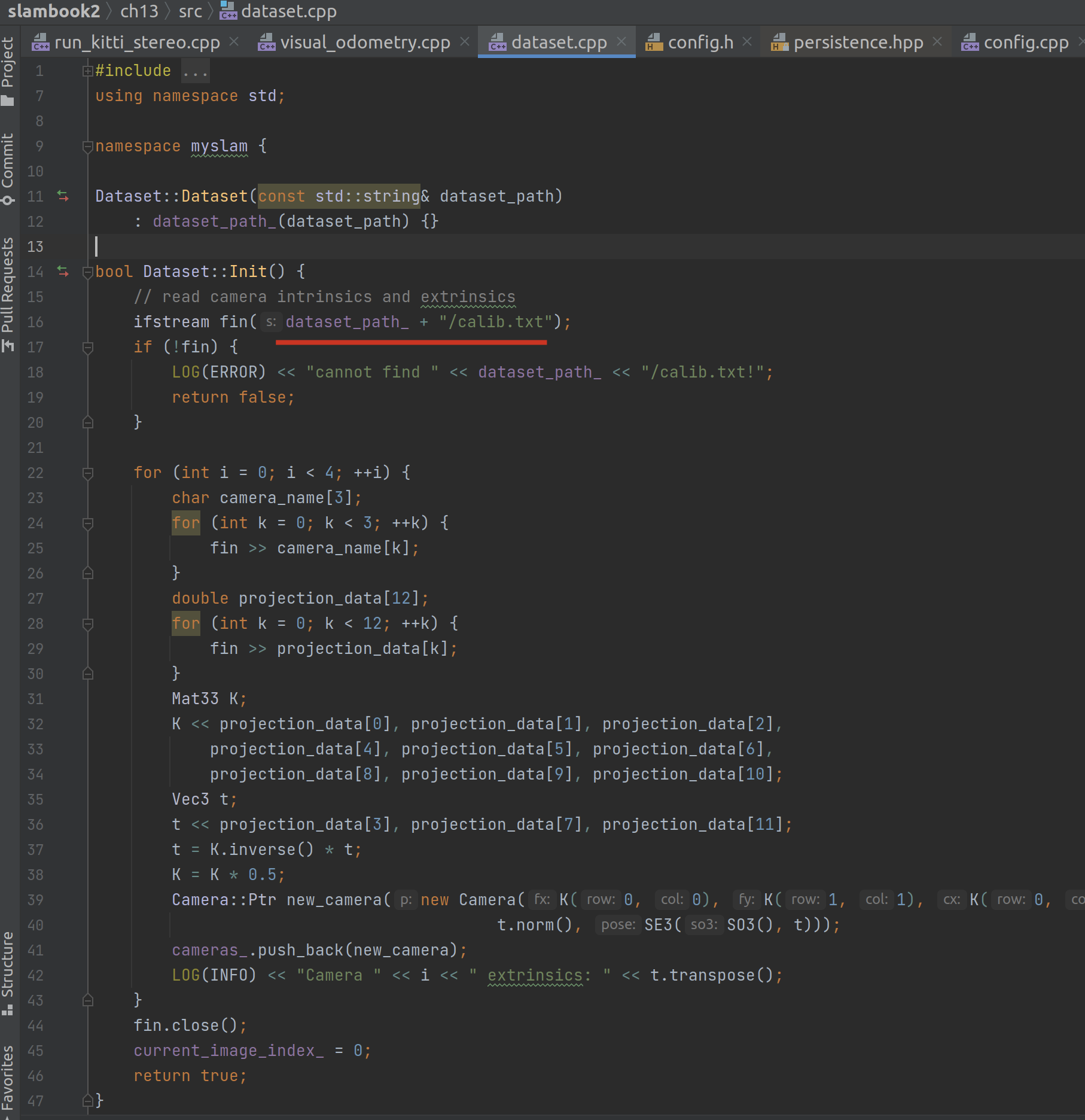
检查我们磁盘上的数据集,确实有这个文件,里面存储着 P0 | P1 | P2 | P3 四个十二维浮点数组。
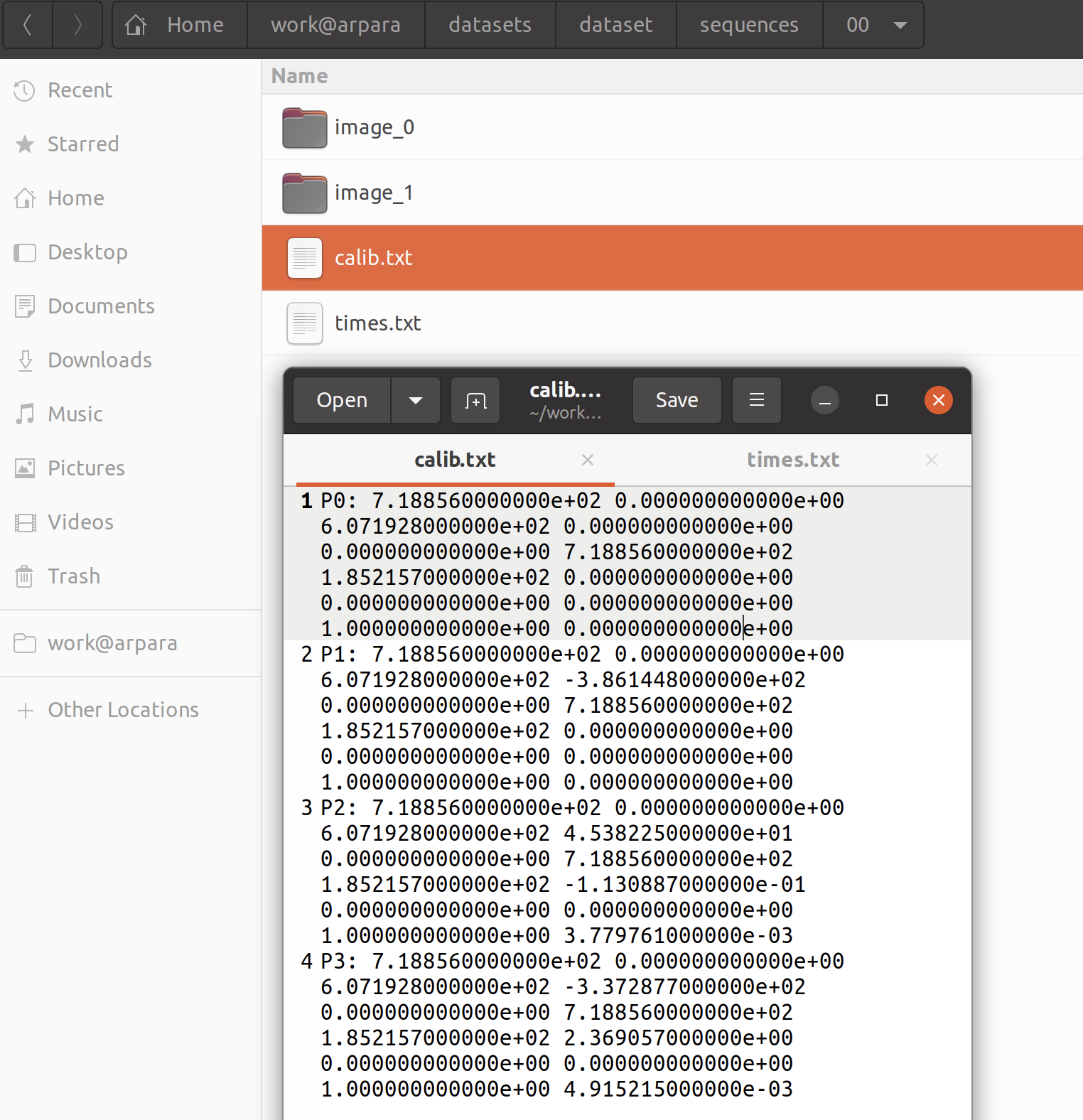
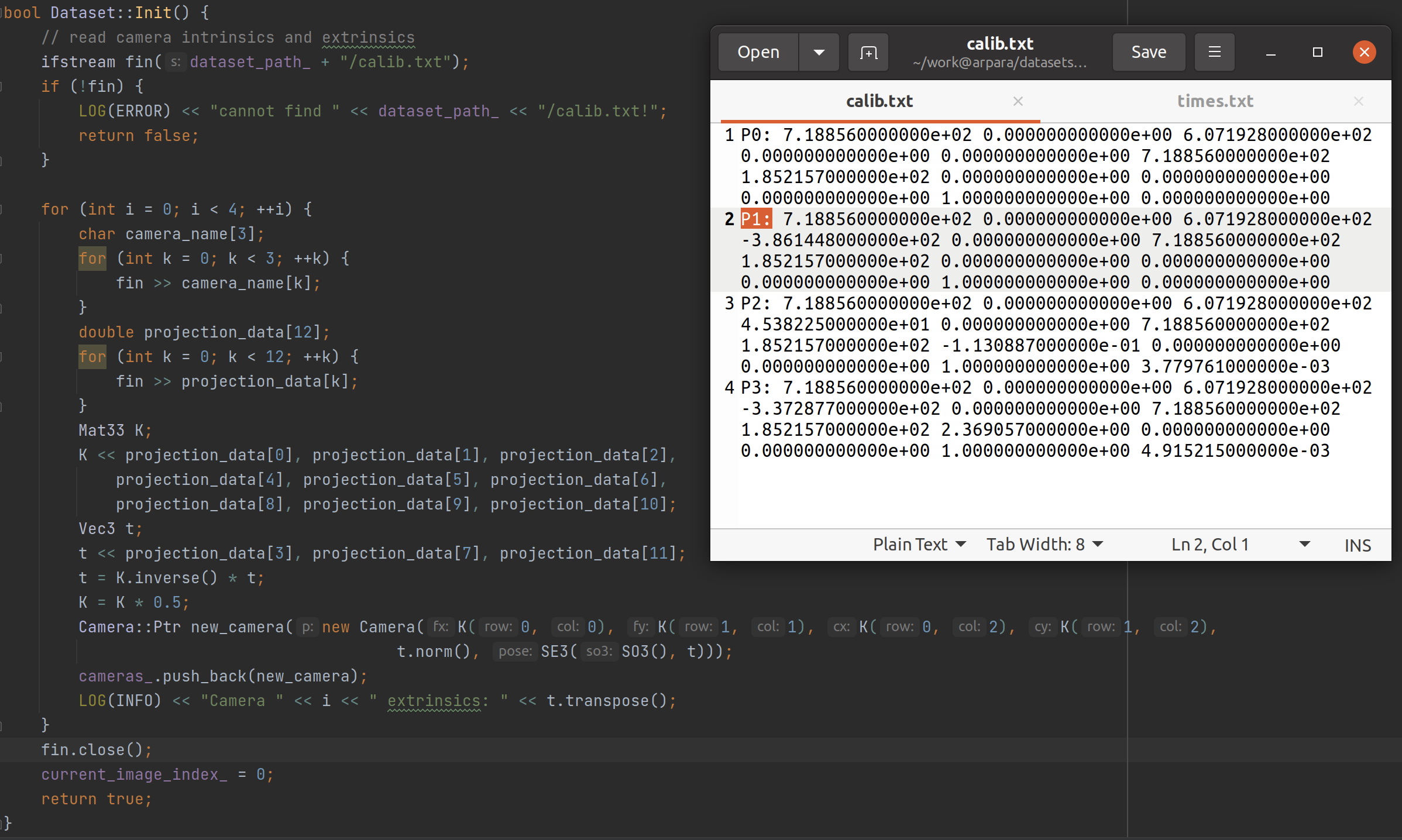
从代码来看,P_i 是相机的命名,而十二个数可分成两部分,前 9 个组成一个 3X3 的矩阵(相机的内参数(Camera Intrinsics)矩阵 K,书 p99),后 3 个是一个向量(平移向量)(p45),即当它表示成 3X4 的矩阵时左边 3X3 的矩阵为相机的内参数矩阵,右边的 3X1 的矩阵为平移向量),因此内参数矩阵录入的数据分别是 0,1,2;4,5,6;8,9,10,而非 0-8。
相机的初始化
相机的初始化要用到六个参数:fx | fy | cx | cy | baseline | pose:
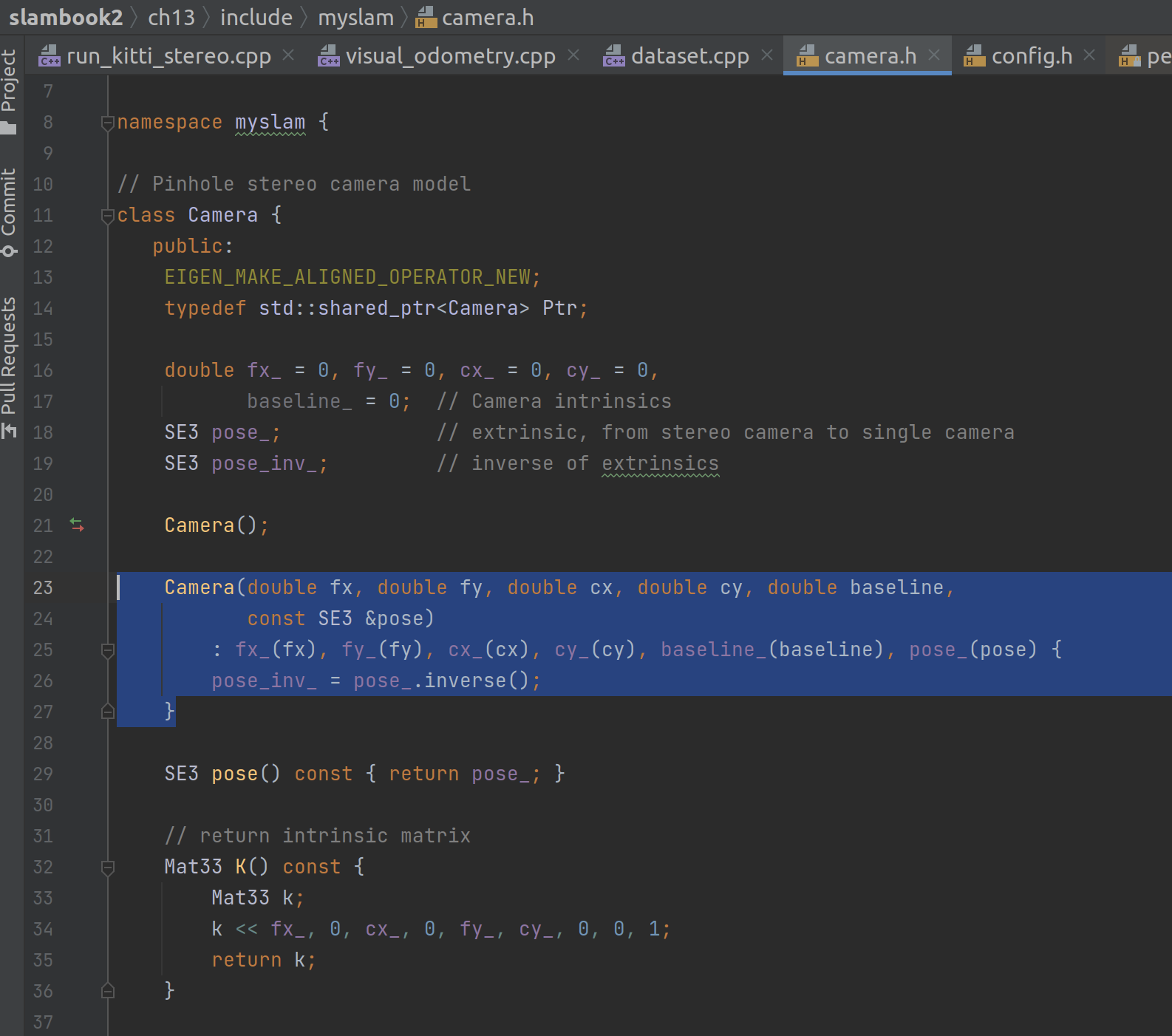
在上层的初始化过程中传入的分别是:
fx = K[0, 0]
fy = K[1, 1]
cx = K[0, 2]
cy = K[1, 2]
baseline = t.norm()
pose = SE3(SO3(), t)
其中 fx | fy | cx | cy 符合相机内参数矩阵 K 的定义(p99):
并且我们可以检验一下,输入数据的第 1、4、8、9 项应为 0,第 10 项应为 1:
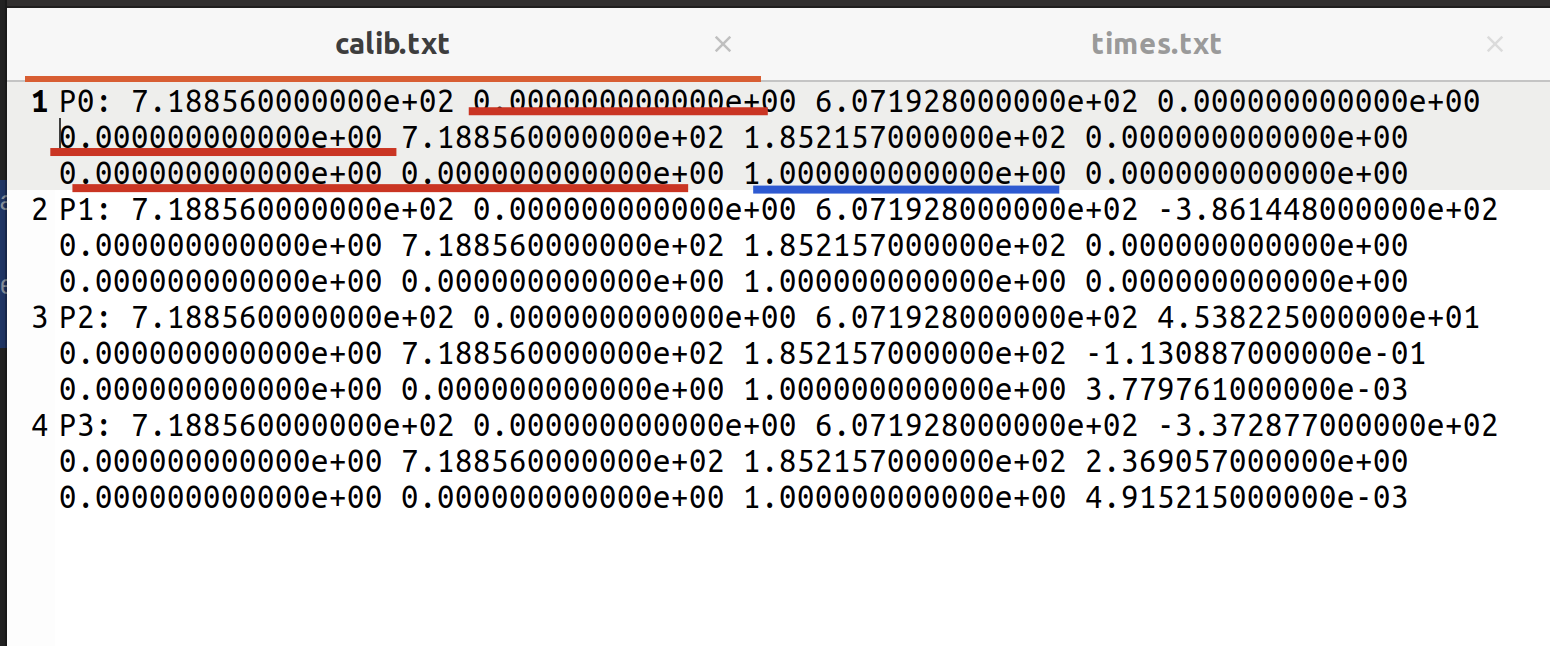
此外,P0 的数据显示,其最后一列(也就是平移向量)其实是一个零矩阵。
!!! question 不过值得注意的是,从读取数据到初始化相机类时,K 有个乘以 0.5 的动作,也就是第十项实际输送时已经变成了 0.5。为啥? 根据hjr553199215/slambook2-ch13-VO-comment: 视觉 SLAM 十四讲 ch13 中 VO 的详细注释版本,基本覆盖所有理解难点,尤其对入门学者十分友好!!里的注释,是由于读取图片时做了缩放,导致投影获得的像素坐标变为了原来的一半所以才乘了一个系数 0.5: 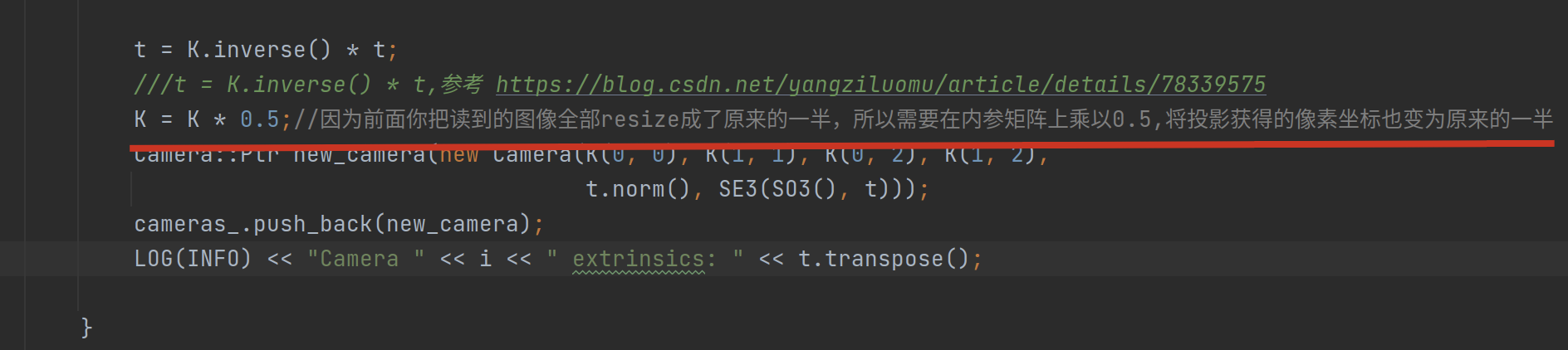
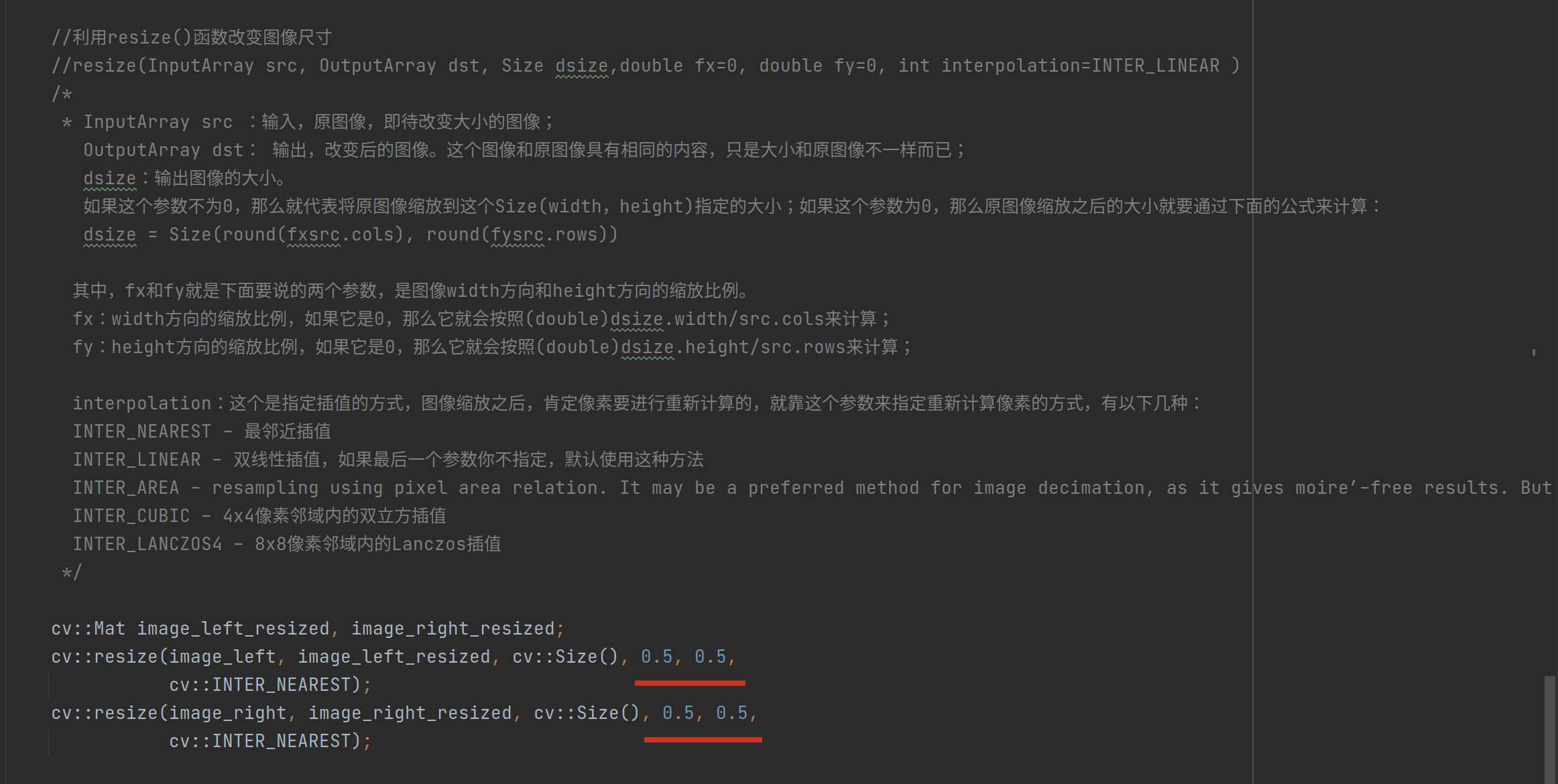
了解原理后,其实这里比较合适的写法是用一个常数,保证同步,不然不知所云。
!!! question 另外书中对基线的定义是两个相机(双目)之间的水平距离(p104),按道理这个应该也是已知的,因此也不知道第 37 行为啥要通过复杂的运算去算出来? 事实上,这个 projction_data 的结构如下calib-file: $ K = \left ( \begin{array}{c:c} \begin{matrix} f_u & 0 & c_x \\ 0 & f_v & c_`y \\ 0 & 0 & 1 \end{matrix} & \begin{matrix} -f_ub_x \\ -f_vb_y \\ 0 \end{matrix} \end{array} \right ) $ 因此,使用 t = K.inverse() * t 的办法可以还原出 ,从而得到 $ t = \begin{pmatrix}b_x \\ b_y \\ 0\end{pmatrix} $ ,最终baseline = t.norm()即 $ t = \sqrt{b_x^2 + b_y^2} $ ,由于我们的,因此 t = b_x即我们的baseline(0.065m)。
> 【猜测】这应该不是高翔的锅,是kitti的一种设计,至少这样能存储更多的信息,也许还包括了点位姿,毕竟baseline总是能解算出来的,而且能够存入矩阵内,比单独的用yaml文件去配要高级!
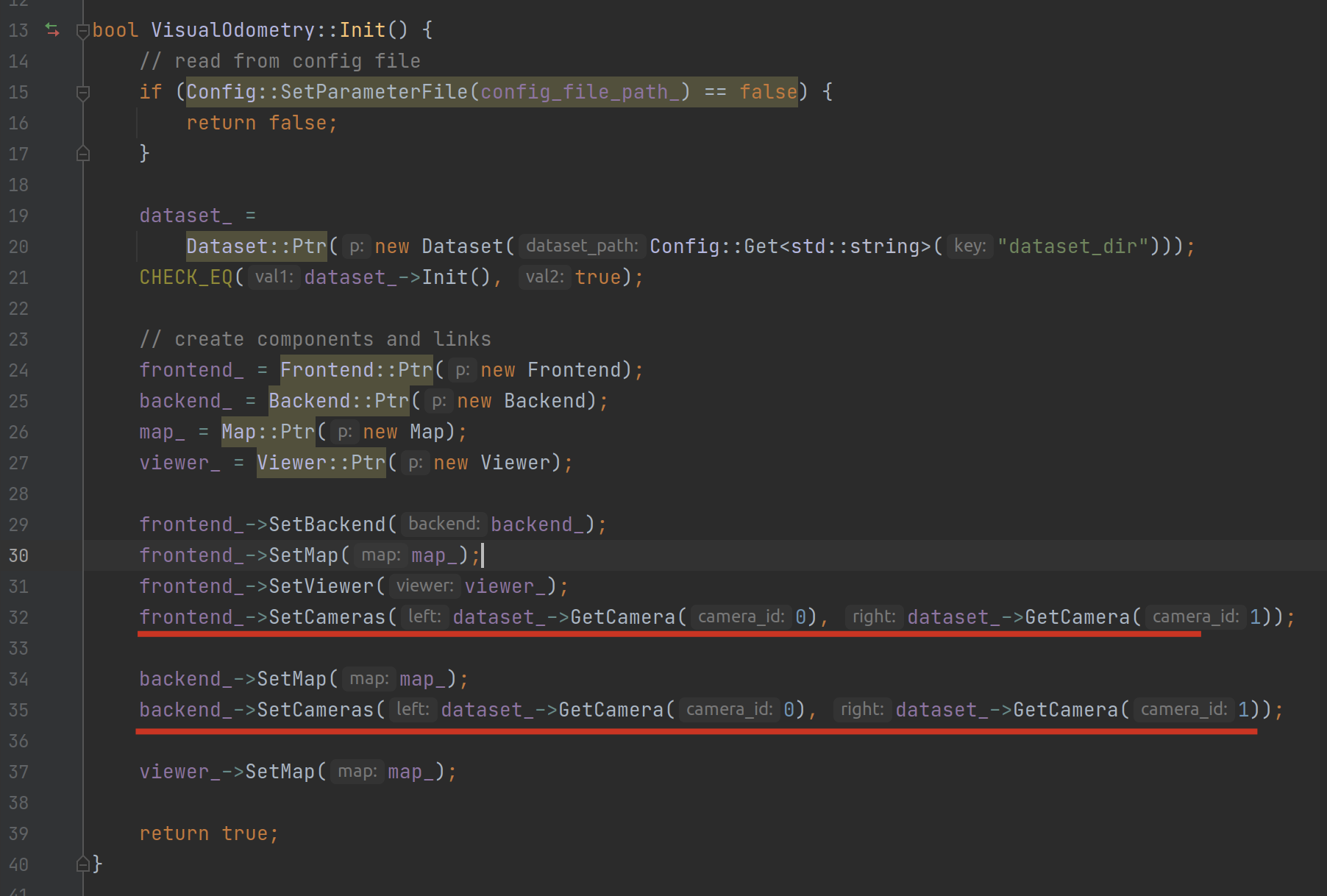
接着就是把第 0 个相机(左眼)和第 1 个相机(右眼)分别送进前端与后端:
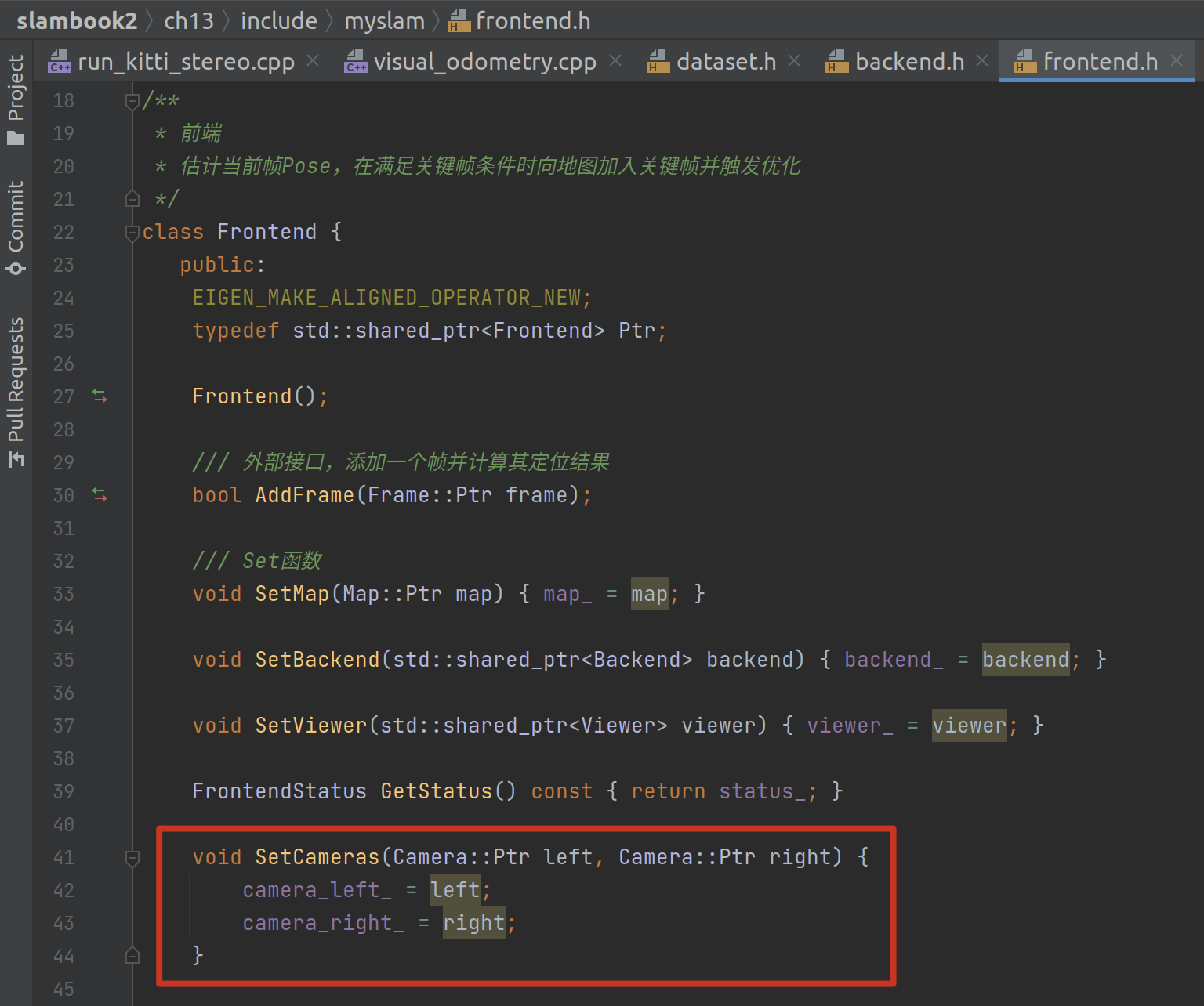
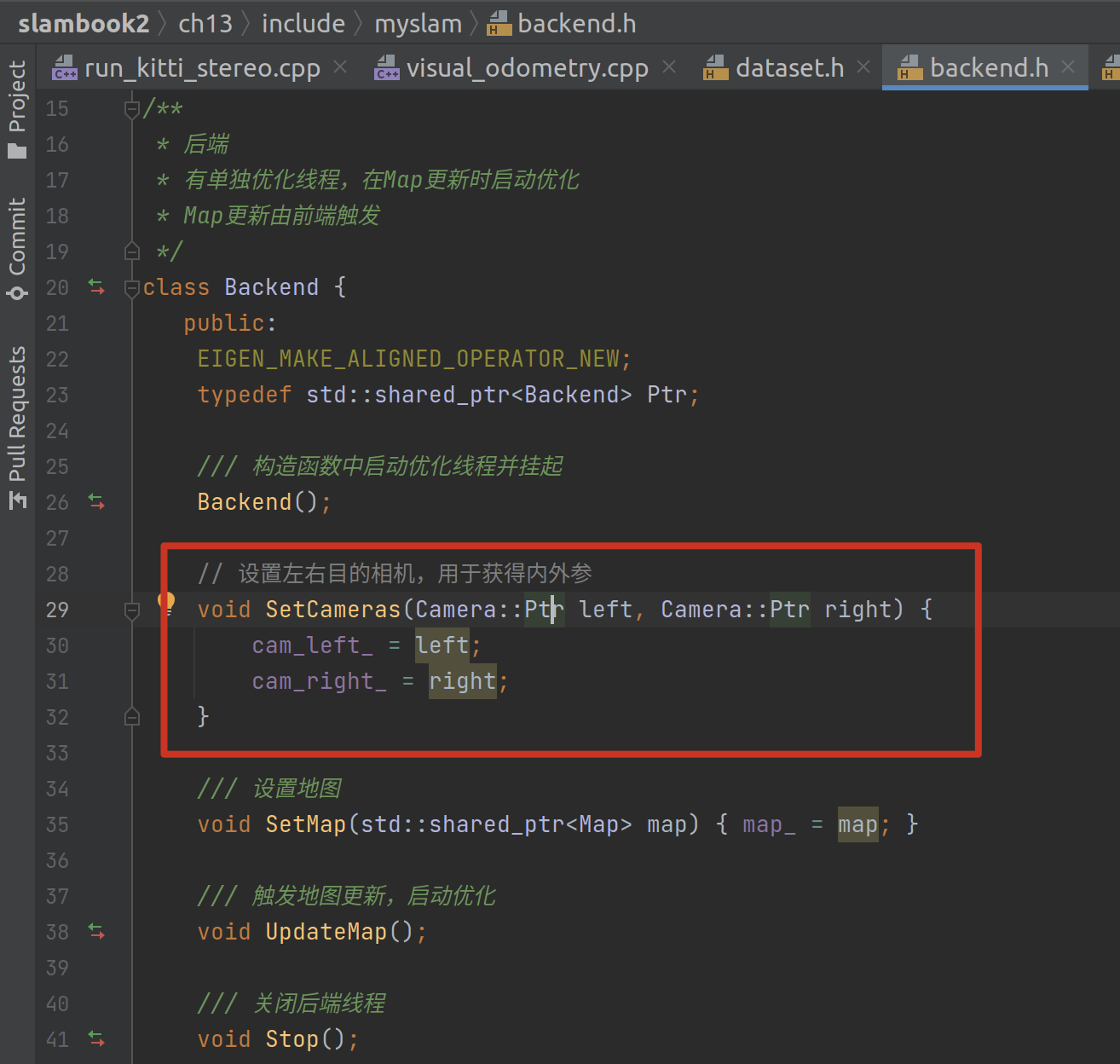
然后就开始跑图了。
跑图 - 数据集遍历
跑图就是一个单步循环:
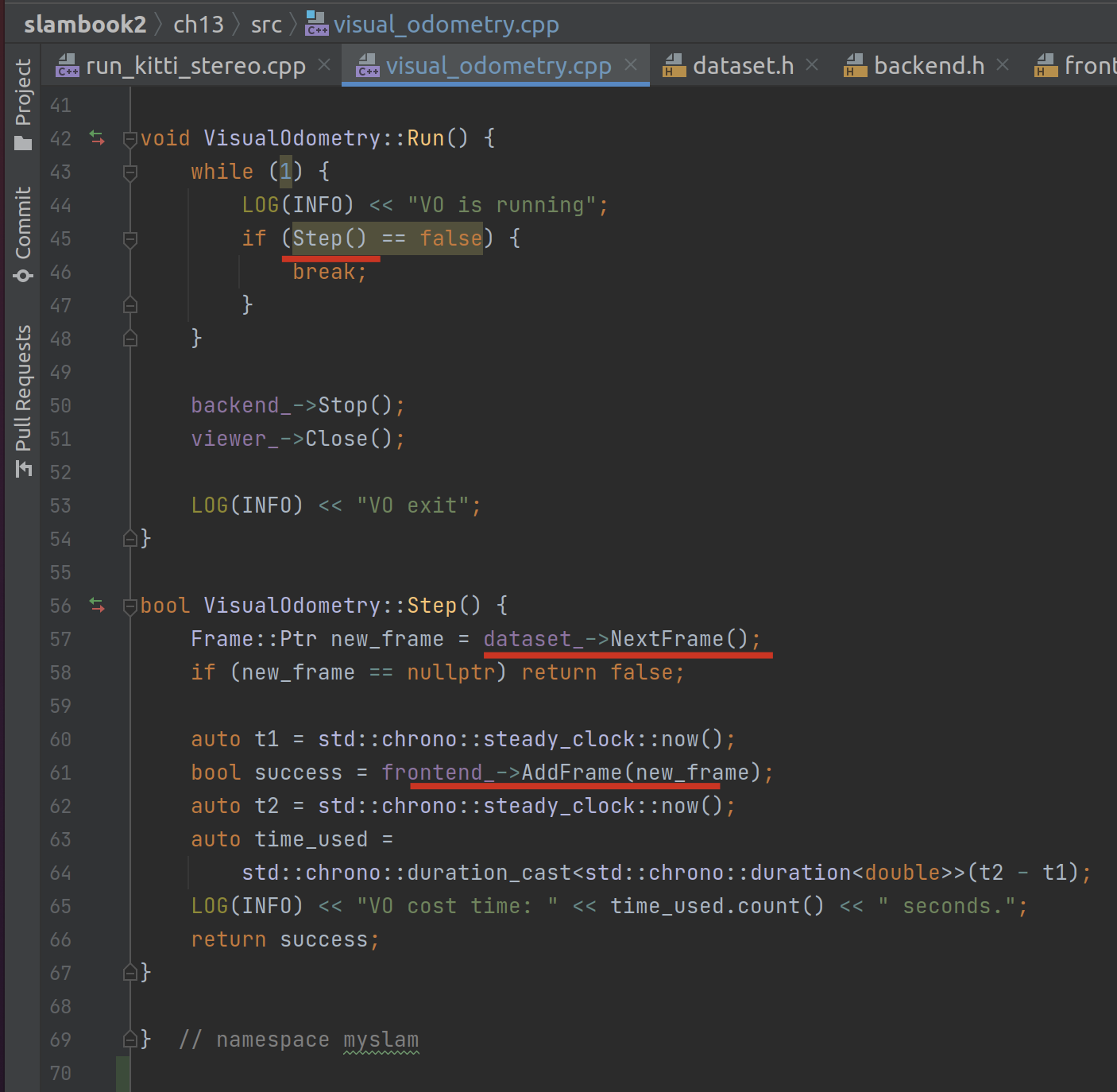
其中最重要的两个逻辑是dataset_->NextFrame获取下一帧与frontend_->AddFrame将新帧加入前端。
其中 dataset_->NextFrame 倒是不难理解(相对于机器学习复杂的矩阵处理来说实在太简单了),就是按照路径把数据集内的图片分别放缩 0.5 倍(这部分后续其实可以变量化)然后加载到左右眼中:
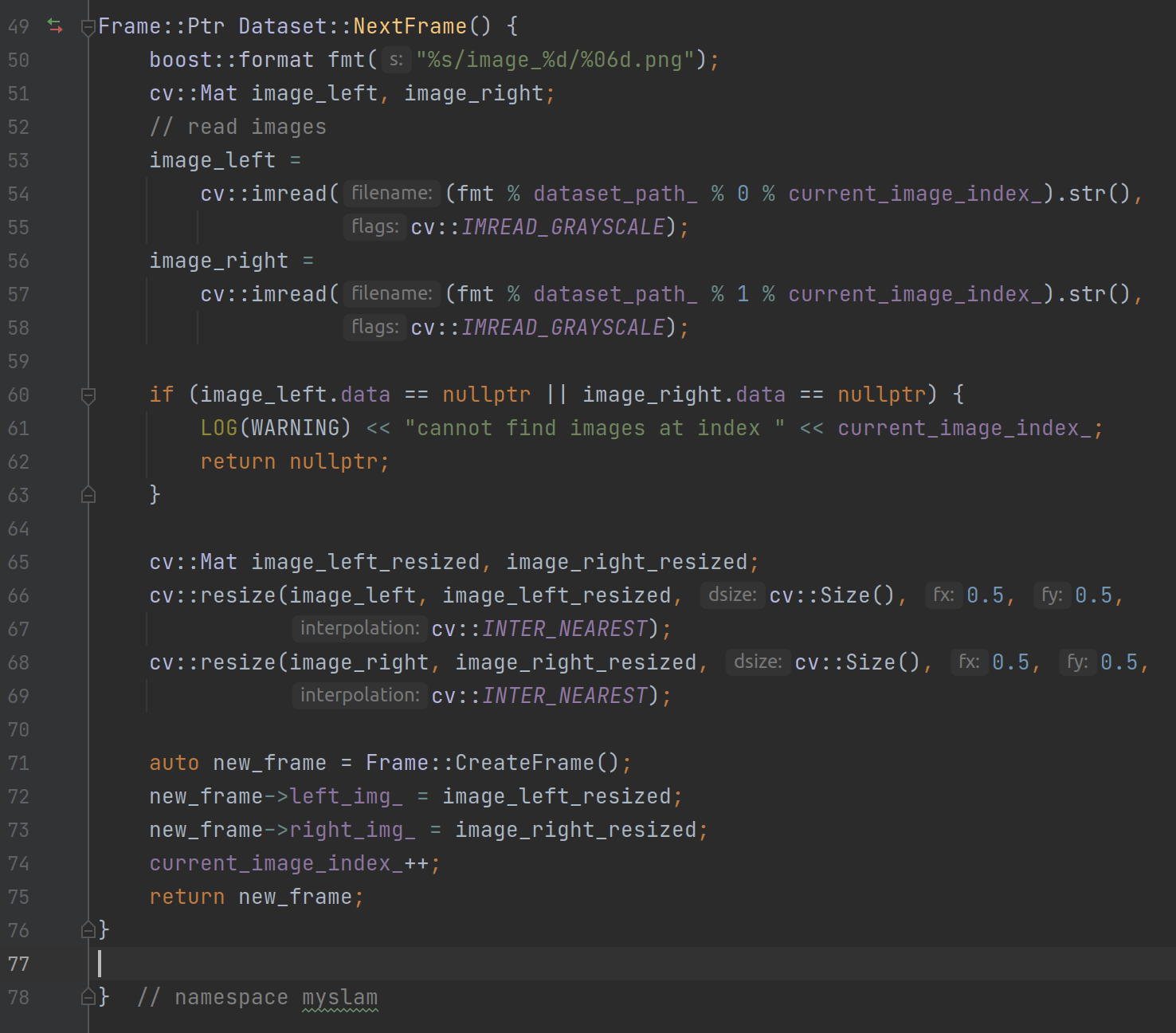
其中文件路径需要符合特定的格式:%s/image_%d/%06d.png,也就是左眼都存放在image_0文件夹下,右眼都存放在image_1文件下,然后每张图片命名为从零(Dataset::current_image_index_)开始的六位左补零整数,格式为 png:
跑图 - 前端帧处理
前端帧处理部分相对比较多,它根据 Frontend 当前的状态决定下一帧的帧处理动作,核心应该是 track 函数。
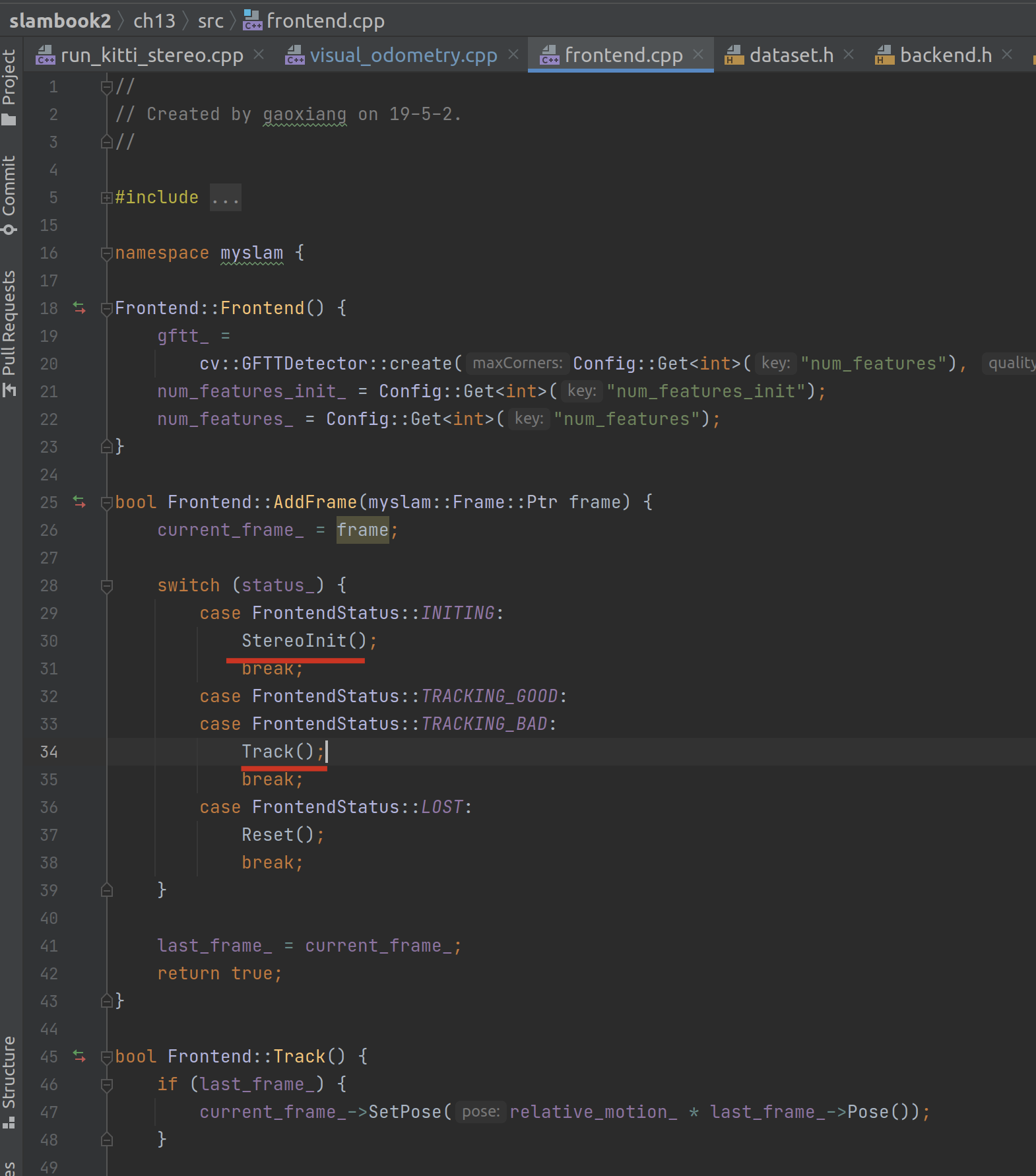
先来看看 StereoInit 的逻辑。
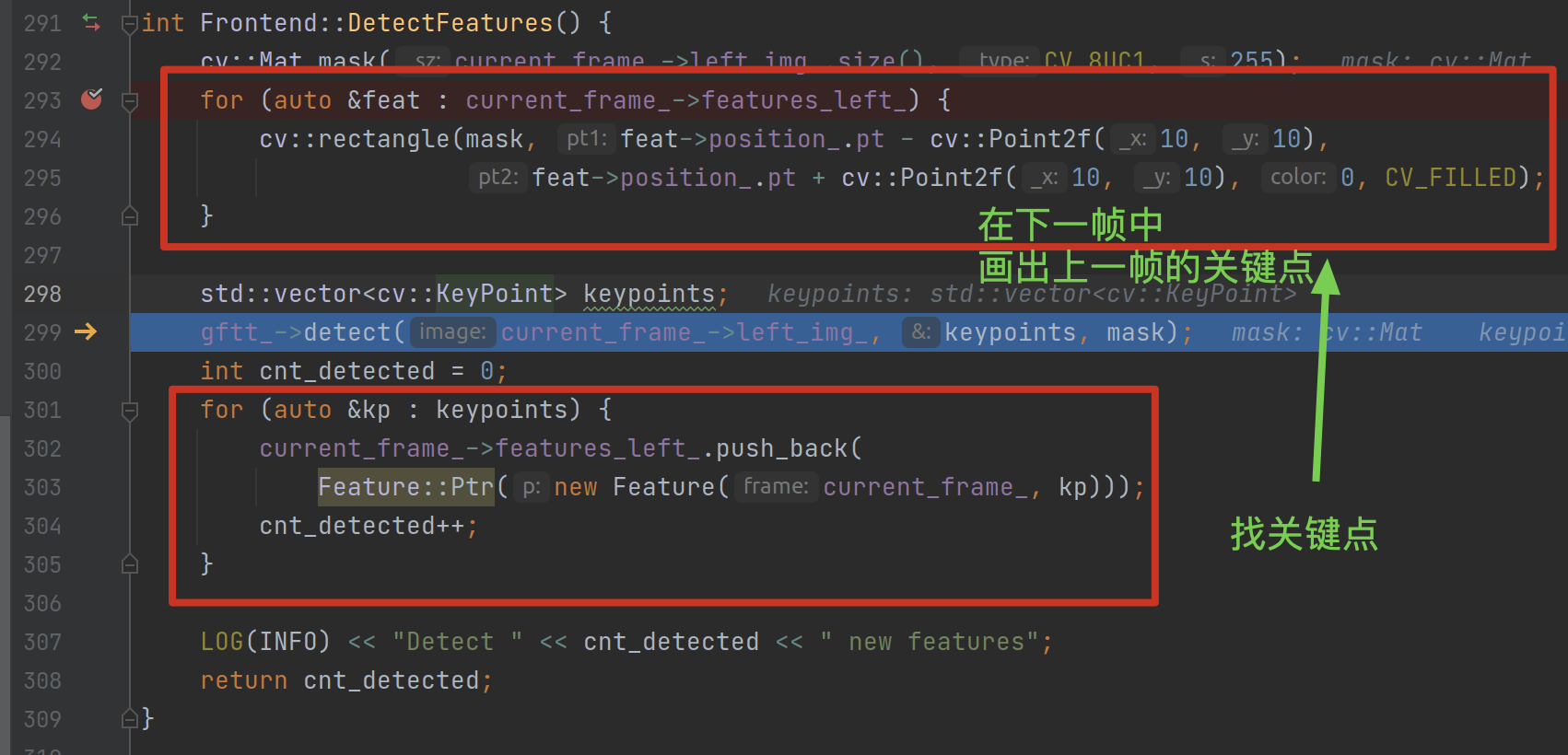
这里面最主要的逻辑其实就是开头的两句,先在左图中寻找特征点的数量,再在右图中使用 LK 光流法去估计点数。这里值得注意的是尽管 IDE 提示 num_features_left 这个变量没有用到,但是它对应的函数 DetectFeatures() 的执行却是必要的。
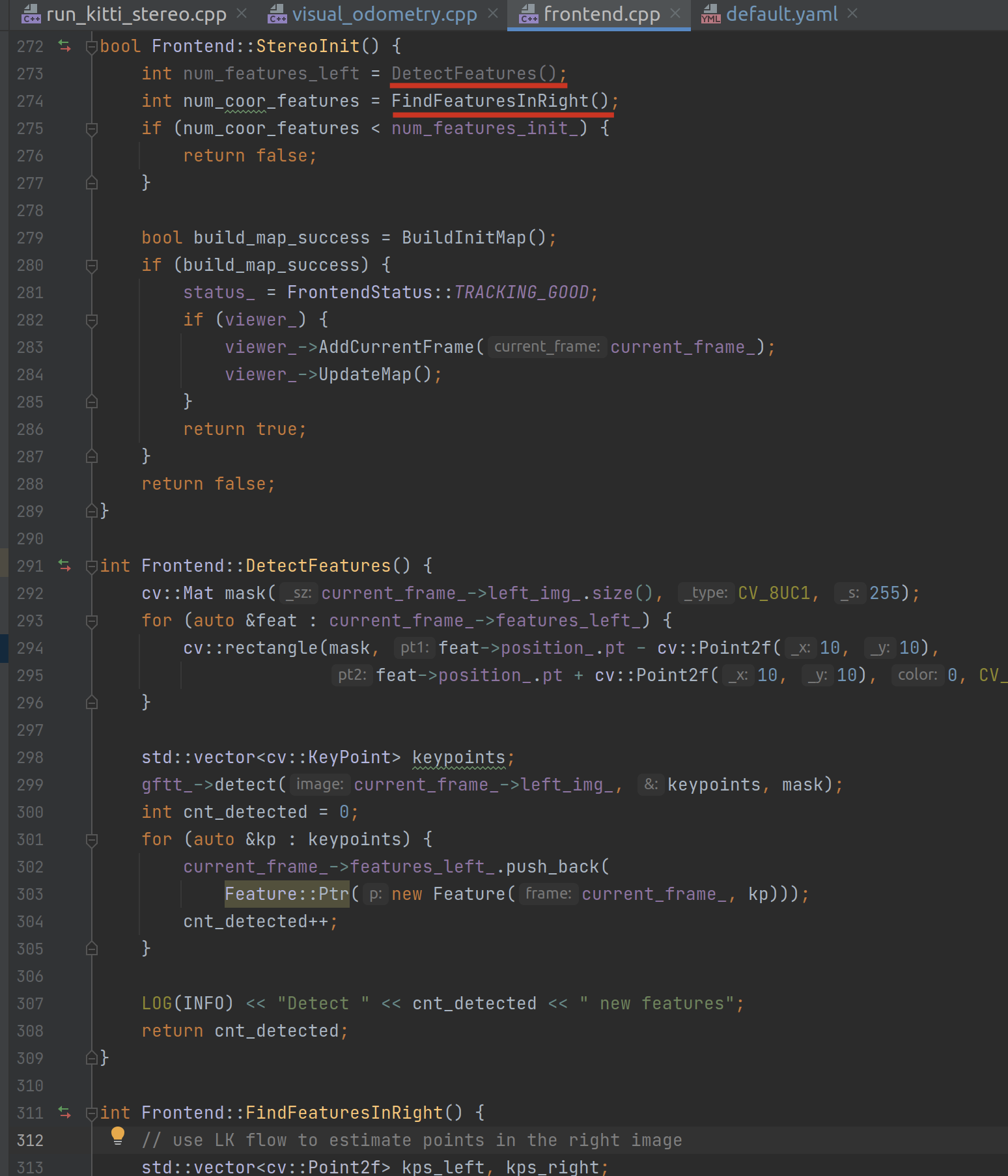
在 DetectFeatures 中对 current_frame_.features_left_ 遍历时,由于 features_left_ 本身是一个向量,因此不会报错,但一开始是空的:
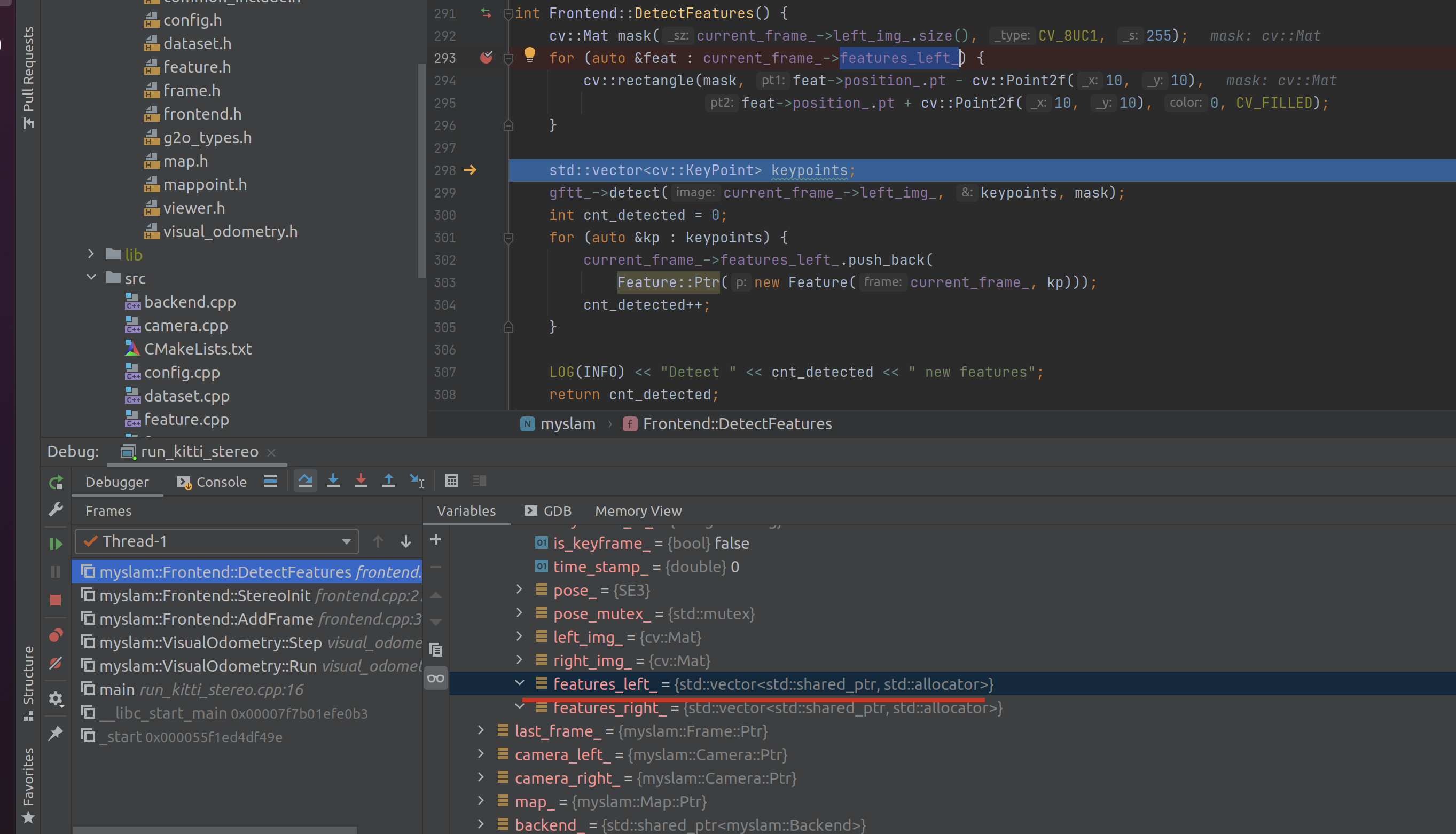
GFTT 是 GoodFeaturesToTrack 的意思:
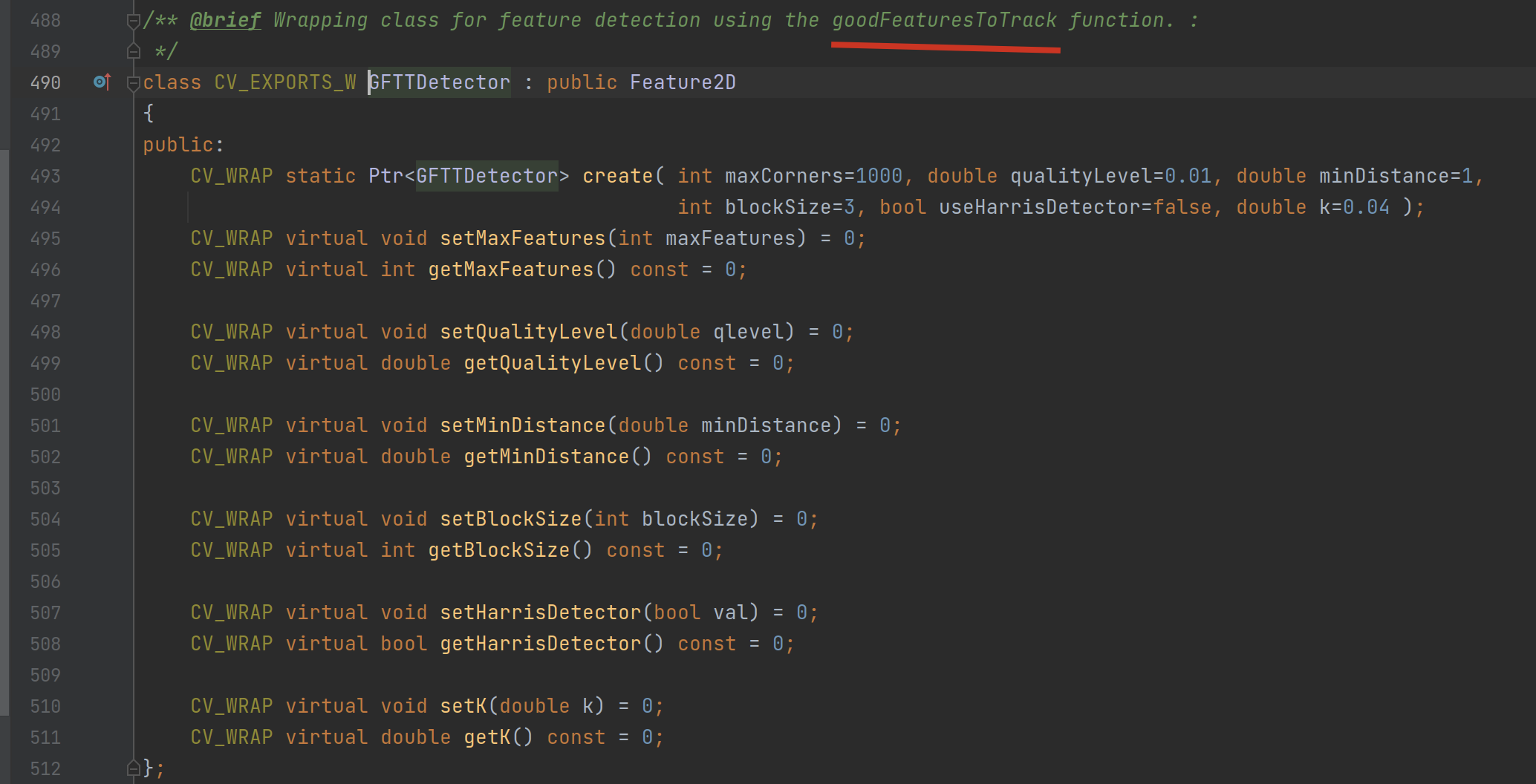
它调用 detect 函数寻找一张图片(或图片集)里的关键点:
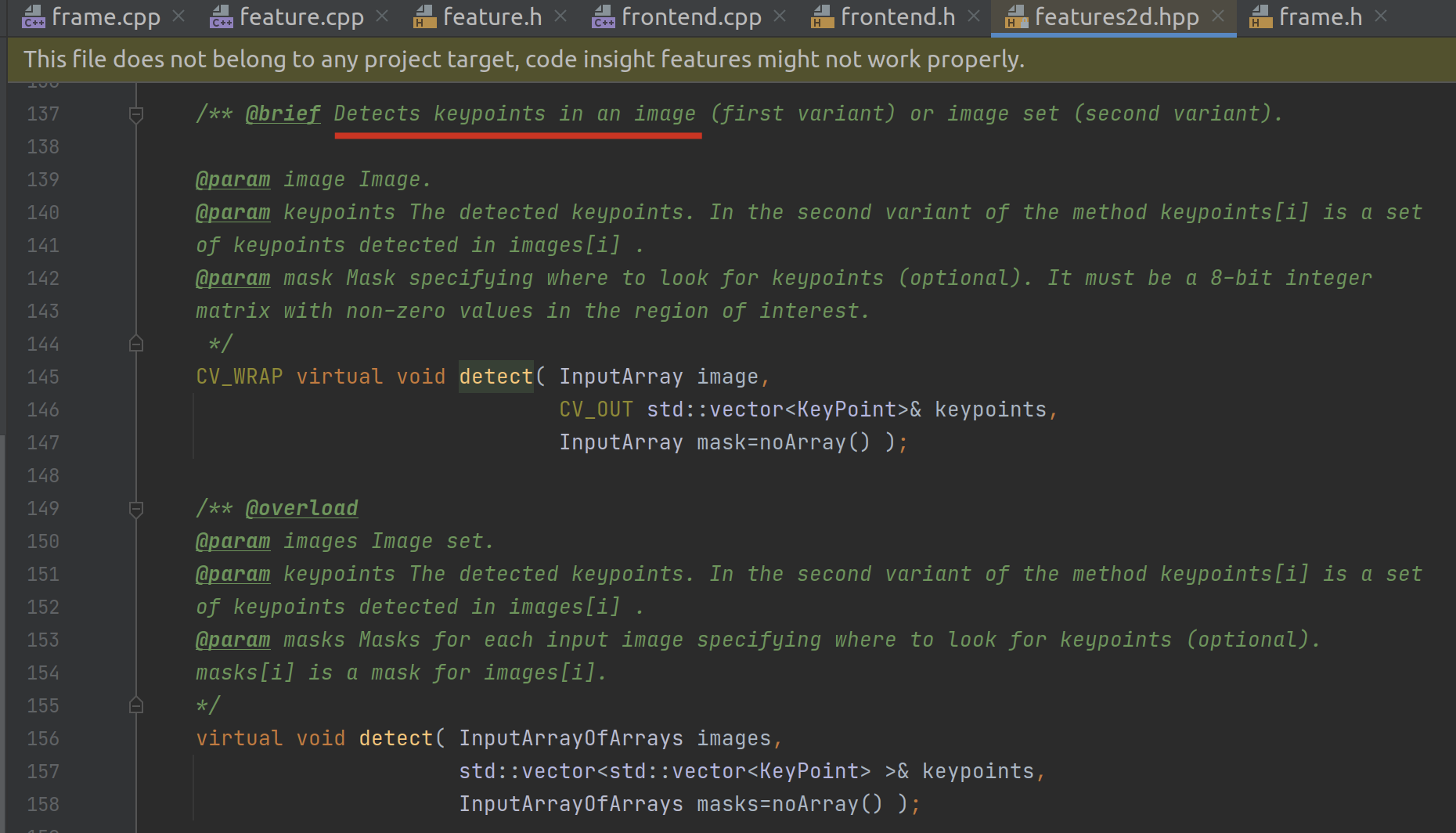
其中,里面的 mask 参数,我们可以直接通过传入图片的 size() 去构造,而不用关心其具体原理,猜测应该是圈定我们需要分析的区域的意思(不确定)。
KeyPoint 数据结构主要是 x 和 y 点(尽管还可以包括很多其他信息):
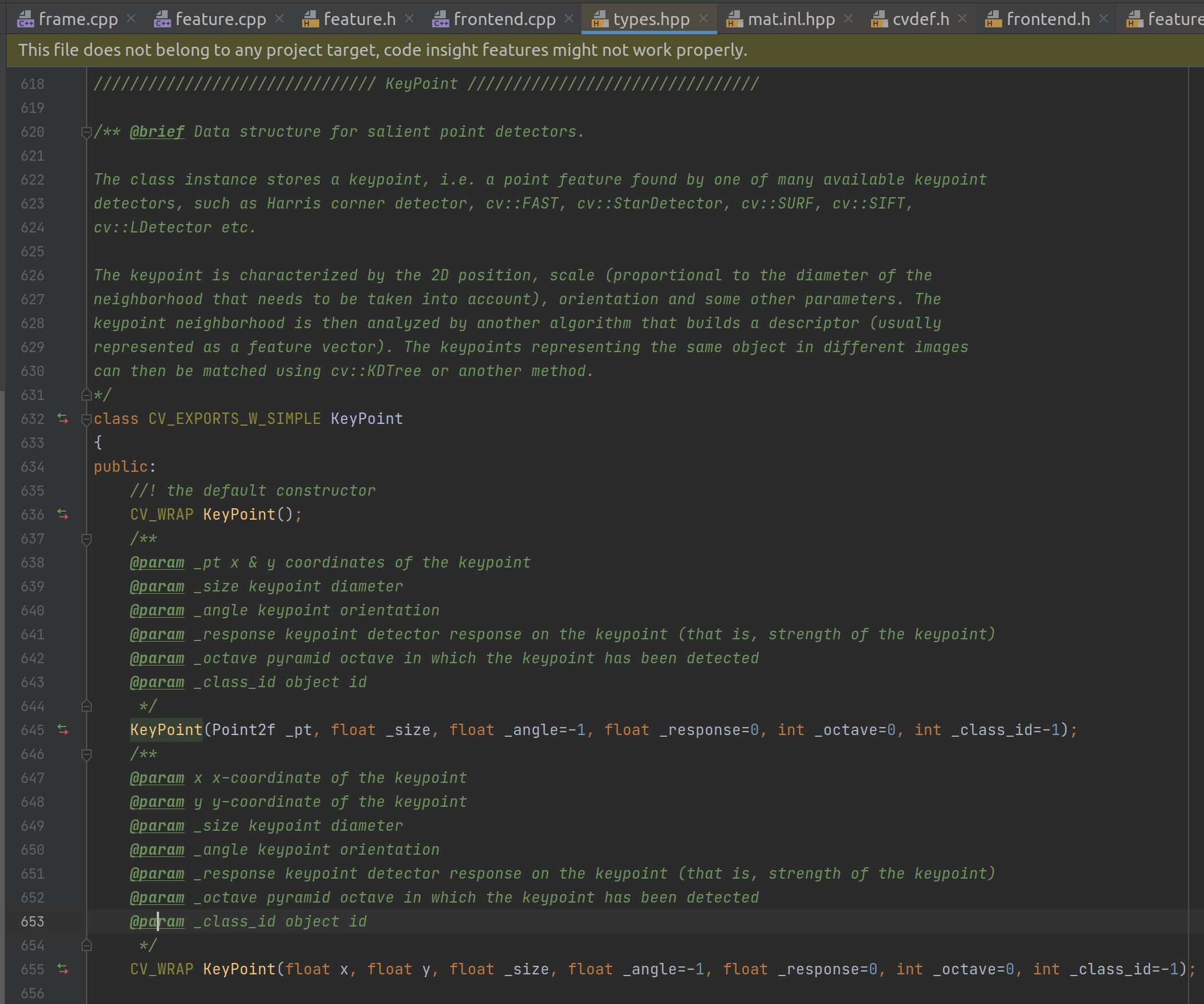
因此整个逻辑就是:
代码整理后如下:
//
// Created by mark on 6/20/22.
// ref: [cv::GFTTDetector特征点检测_酸菜余的博客-CSDN博客](https://blog.csdn.net/weixin_43821376/article/details/100135901)
//
#include "cv.hpp"
/**
* detect keypoints from an image
* @param img
* @return
*/
std::vector<cv::KeyPoint> detectKeyPoints(cv::Mat &img) {
std::vector<cv::KeyPoint> detectedKeyPoints;
cv::Ptr<cv::GFTTDetector> gftt_ = cv::GFTTDetector::create();;
gftt_->detect(img, detectedKeyPoints);
return detectedKeyPoints;
}
/**
* draw keypoints on the image, the effect depends on the match degree
* @param img
* @param detectedKeyPoints
* @param title
* @return
*/
cv::Mat drawImgWithKeyPoints(cv::Mat &img, std::vector<cv::KeyPoint> &detectedKeyPoints,
const std::string& title) {
cv::Mat imgWithKeyPoints;
drawKeypoints(img, detectedKeyPoints, imgWithKeyPoints, cv::Scalar(0, 0, 255),
cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS);
imshow(title, imgWithKeyPoints);
while (cv::waitKey(0) != 32);
return imgWithKeyPoints;
}
int main(int argc, char *argv[]) {
std::string imgPath = "/home/mark/work@arpara/datasets/dataset-0610-kitti/dataset02_head-around/image_0/000000.png";
std::string imgName = imgPath.substr(imgPath.find_last_of("/\\") + 1);
cv::Mat img = cv::imread(imgPath, CV_LOAD_IMAGE_GRAYSCALE);
std::vector<cv::KeyPoint> detectedKeyPoints = detectKeyPoints(img);
drawImgWithKeyPoints(img, detectedKeyPoints, "draw img with keypoints");
return 0;
}
测试与实现
发现 1:ch13 的代码检测特征点的办法不符合我们的场景需求
在 ch13 中检测左图特征点的代码位于 Frontend::DetectFeatures 中,而在这个函数内的操作主要分两步,第一步是把上一帧检测出的特征点给画在当前帧上,第二步就是继续检测本帧的特征点。
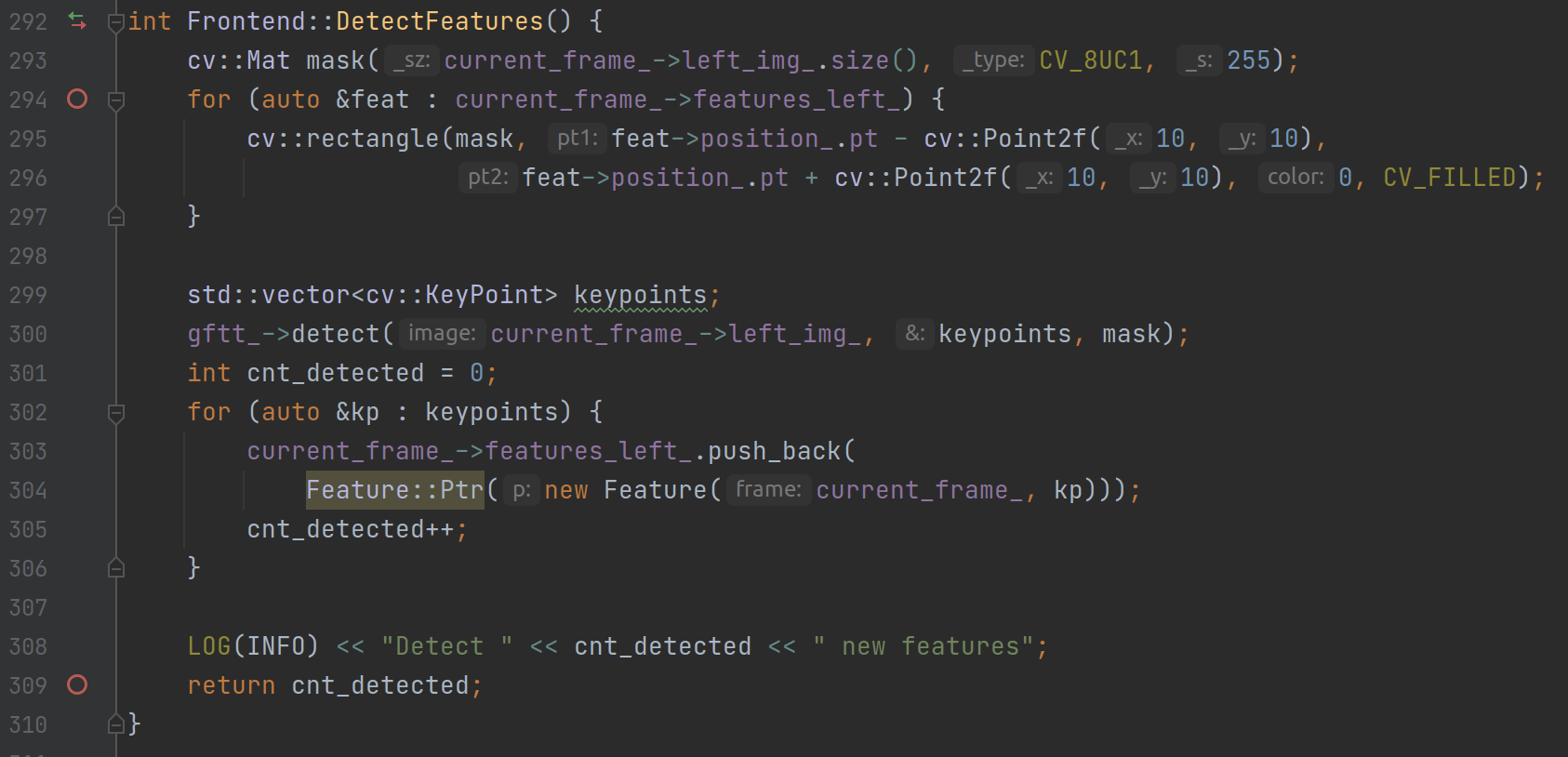
但我们在初期测试验证时,并不需要这么复杂,只需要在检测出当前帧的特征点后,然后绘制验证即可。
此外,函数中使用了一个 mask 变量用以限定检测特征点的区域,这对于我们来说似乎也没有必要加上。而且这个 mask 目前使用的是全图大小,然后为单色,相当于没有不限定的意思:
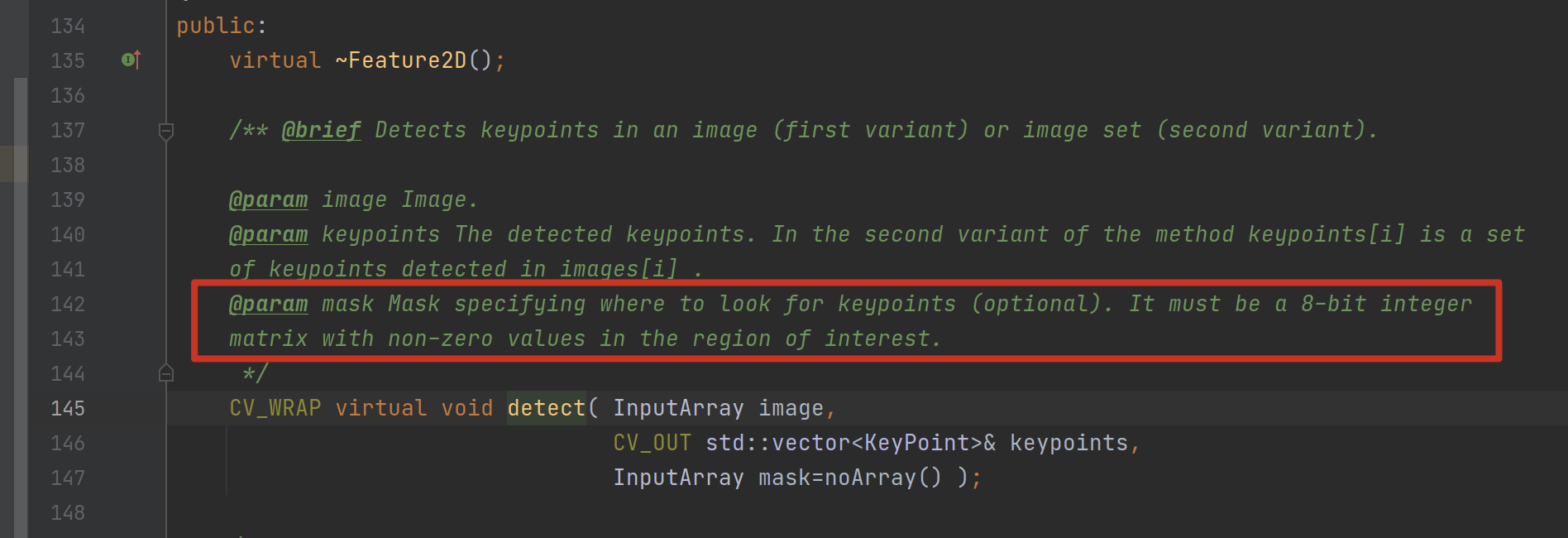
最后,影响最终检测效果的关键参数,是在 cv::Ptr<cv::GFTTDetector> gftt_ 的初始化上:

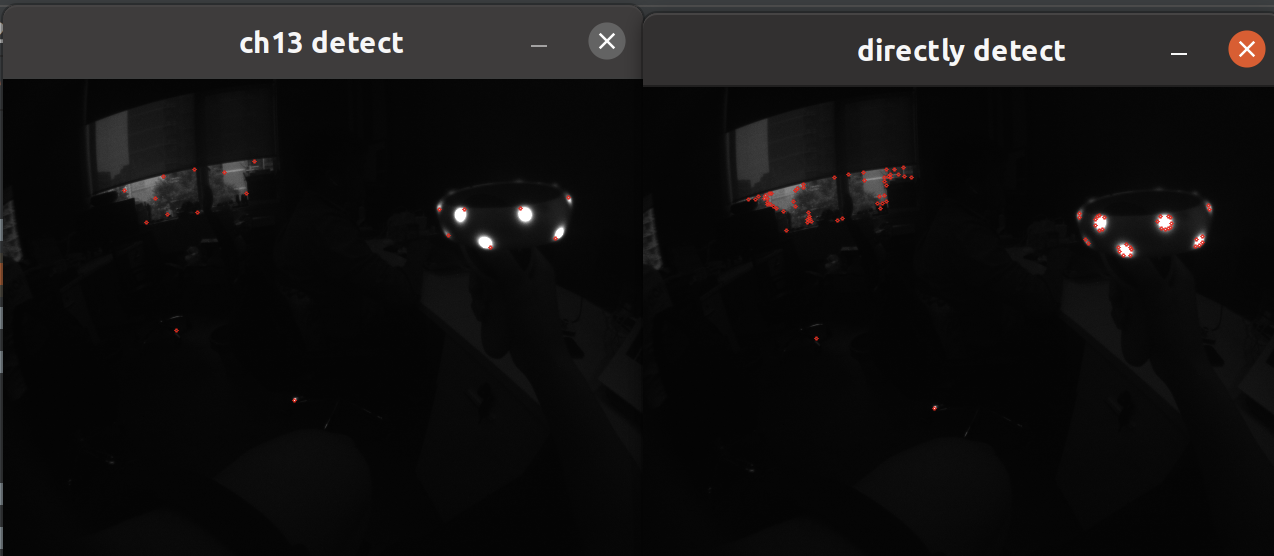
可以看到,目前 ch13 初始化gftt_的参数中,第一个参数是特征点的最大数目,由配置文件输入(150);第二个参数是质量等级;第三个参数是最小距离。
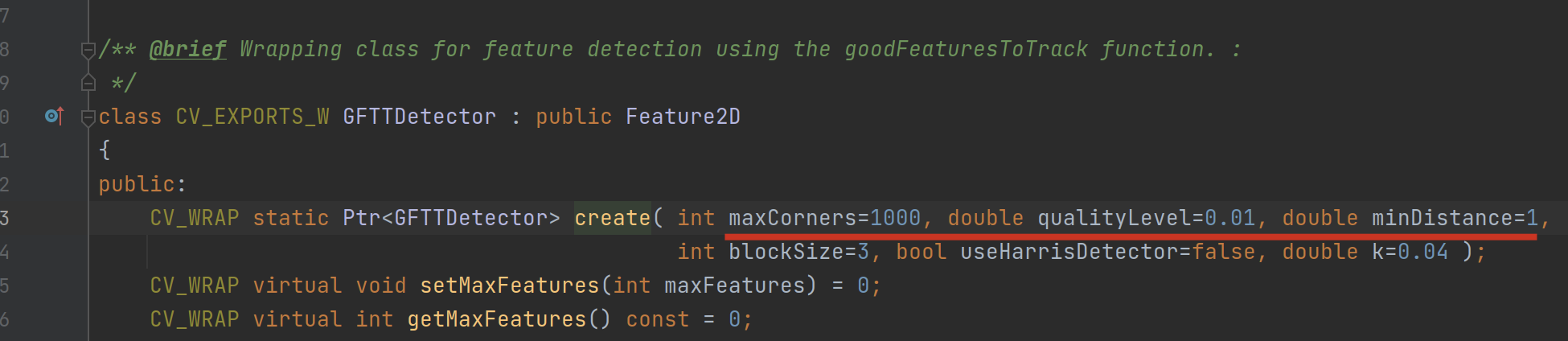
重点在这个最小距离上,默认是 1(单位应该是像素),这样可以把我们手柄上的灯一圈给完整识别出来;而 ch13 中配的是 20,就会导致一圈灯只能检测到一两个特征点,这个是严重不符合我们的场景目标的,我们就应该尽可能多地检测出手柄上的灯相关的特征!
以下就是我们分别以 ch13 设置与默认设置对同一张手柄输出图的检测效果,可以看到一个点比较稀疏,一个点比较密集,有相当大的差异:
其他
如何 debug
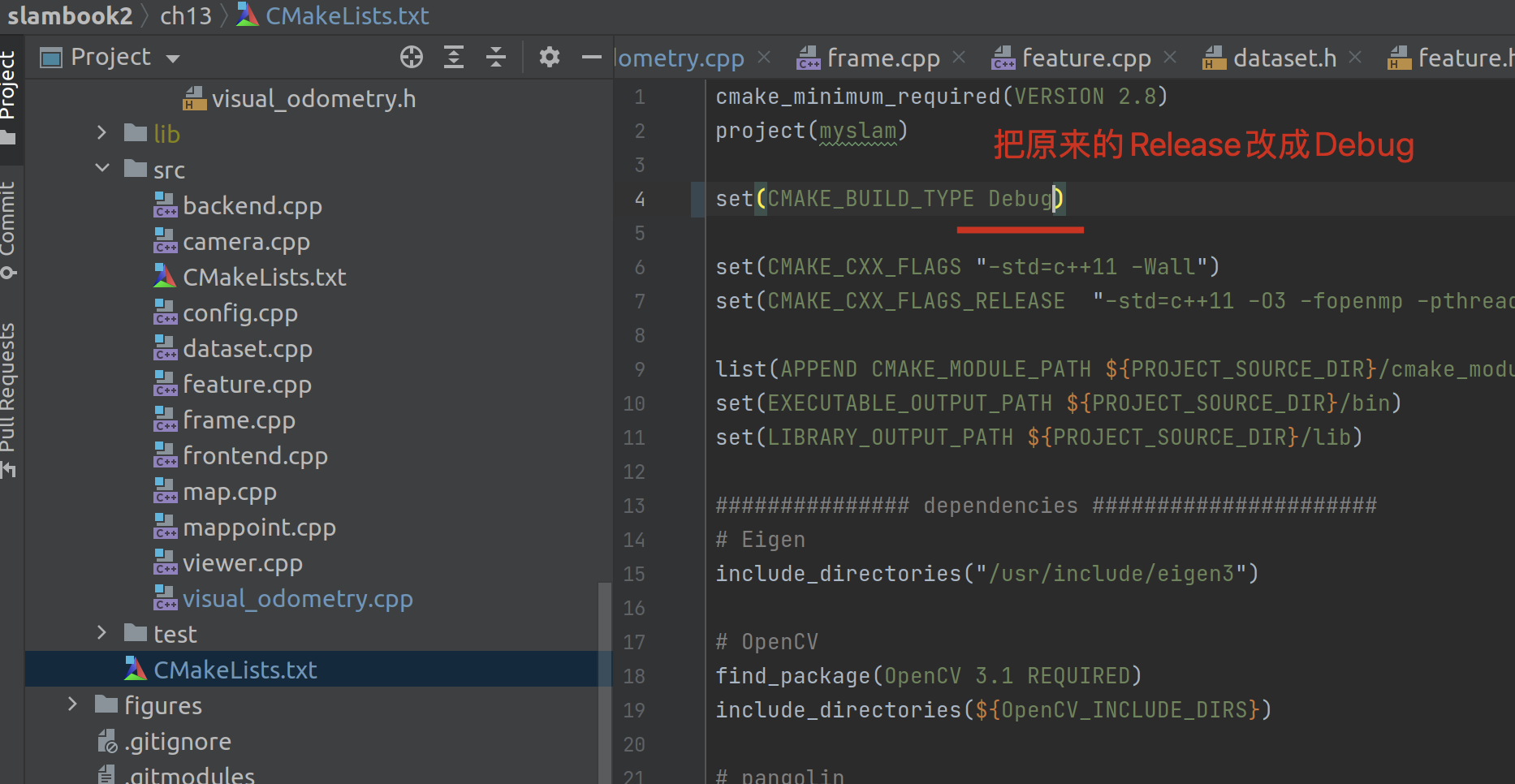
为了查看一些运行逻辑,我们需要 debug,但是在 clion 中光打断点然后 debug 是不行的,还要更改我们的编译类型:
- calib-file
参考:
- ★★★ 对 github-slambook2 的提问,也都是我想问的:请教 ch13(设计 SLAM 系统)中 src/dataset.cpp 中的代码含义 · Issue #213 · gaoxiang12/slambook2
- ★★ 给出了第一行的表达式:KITTI 数据集测试 - 3 calib 相机参数_旧人赋荒年的博客-CSDN 博客_kitti 相机参数
- ★★ 给出了第二行的表达式:computer vision - kitti dataset camera projection matrix - Stack Overflow
- computer vision - Format of parameters in KITTI's calibration file - Stack Overflow
- computer vision - How to understand the KITTI camera calibration files? - Stack Overflow
- image processing - How Kitti calibration matrix was calculated? - Stack Overflow
- 关于 dataset.cpp 中外参平移向量的问题 · Issue #1 · hjr553199215/slambook2-ch13-VO-comment