- 概要
- 秒换装概念与分析
- 秒换装的难度阶梯
- 备战出装换装的优点
- 备战出装换装的缺点
- 换指定装的实现分析
- iOS 秒换装实现之语音控制(Voice Control)实现自定义手势
- iOS 秒换装实现之越狱、第三方应用
- 秒换装实现之基于外设硬件
- iOS 秒换装实现之基于 iOS 自动化:
facebook-wda(WebDriverAgent) - UI 自动化的缺点(行走中的触控集成问题)
- 多点触控集成
- 封号的风险
- 需要 USB 接入
本篇主要讲解在 iOS 平台上如何实现王者荣耀一键换装。安卓由于有adb的存在,自动化远比 iOS 简单的多得多,因此不在本文探讨范畴内,感兴趣地可以参阅以前发的笔记:
【文章:安卓系统】
(其实主要是自己目前用 iOS 比较多,所以懒得再写 Android 部分)
本文核心参考:
秒换装概念与分析
众所周知,王者荣耀的高端局经常涉及到两个骚操作:秒换装、三指操作。本篇主要将秒换装的操作,三指的话随缘说吧。
秒换装的难度阶梯
不同的换装顺序难度是不同的。
最简单的是换复活甲,因为复活甲的缓冲时间是 2 秒,并且大多数情况下复活甲是用在对方一波技能打完之后:

其次是换金身,缓冲时间是 1.5 秒。但直到现在,我金身换其他(复活甲、名刀)等都换不来,原因是金身是主动释放,一般都是躲技能的紧急时刻,手忙脚乱的。

接着是名刀,缓冲时间只有 1 秒,远程英雄(例如我的诸葛)直接减半。0.5 秒是真地只能换个锤子了。不过名刀其实比金身要好一些,因为触发名刀的场景大多数情况下是在跑路的时候,这个时候不需要什么其他操作,边走边换就可以。

而换装的核心操作,就是首先先在商店预选好下一件装备(通常走在路上的时候),或者基于预先设置好的出装顺序(缺点等会说)。然后就可以通过四次点击实现换装,在不引起混淆的情况下,我们称这种换装为“一键换装”:
- 点击商店
- 点击卖出
- 点击关闭
- 点击购买(第一个推荐装备,如果钱够的话)
换的核心是卖掉一个再买进一个,如果格子还没满,钱又多,就不存在换的问题,直接就到第四步,这个没啥操作。但如果格子满了,或者钱不够,就需要极快地时间内精准地按下四个键,这个要求是很高的。反正我也曾经尝试在训练营中练过会,表示紧张时刻并不能跟的上。
因此需要自动化!毕竟,为这样一款游戏苦练换装的手速是不值得的。
备战出装换装的优点
备战出装换装的优点也是很显著的,我们可以很简单地备战最后一套出装顺序是复活甲、金身、名刀、血手、炽热支配者。
这样,假设我们有一键换装脚本,即可轻轻松松地按顺序秒换复活甲、金身、名刀、血手、炽热支配者,十秒换五装。
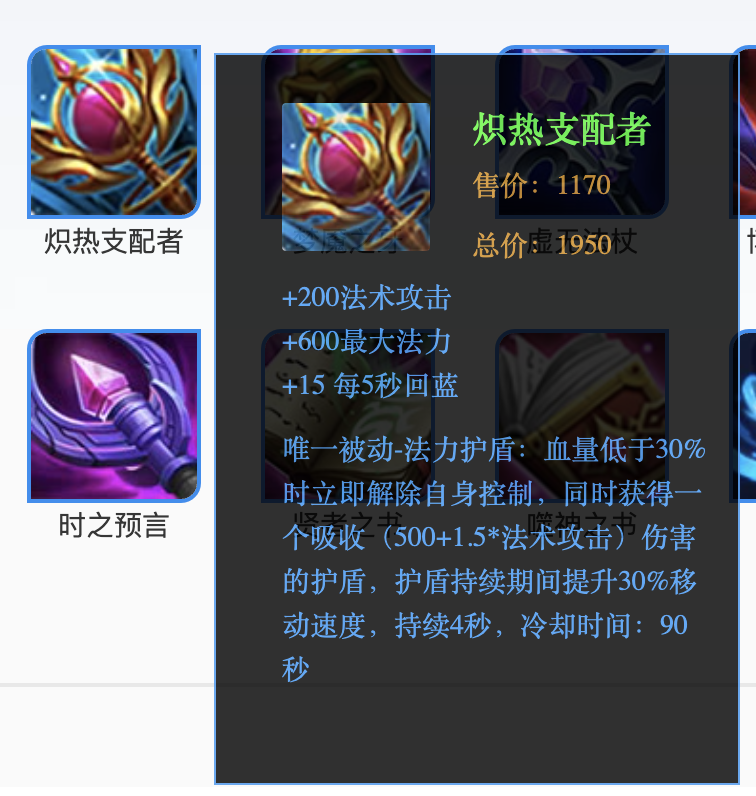
备战出装换装的缺点
首先是不灵活,局越高端,就越需要针对对方阵容出装,此时的备战出装如果只有一套的话,就很不灵活了。
我很久以前喜欢玩中单诸葛的时候,就预设了三套出装:暴力(回响+帽子+大书)、防近身(帽子换面具、大书换法穿棒)、防回血(回响换梦魇)。现在比较喜欢在局中随机应变了,但这就引发了新的问题:顺序问题,即如果局中先买了其他装备,则有可能会影响预期顺序。
例如假设原先六神装最后两件一次是法穿杖、复活甲,由于逆风局中途先出了个魔女抗压,然后快六神的时候,按照顺序第六件变成了法穿杖,第七件才是复活甲,所以按照默认顺序的话,危机关头一键换装就没有换到想要的复活甲。
所以”手动“预选下一件换装装备的必要性还是有的。
换指定装的实现分析
有些场景下,我们需要换指定装,尤其是复活甲。
比如无论你在玩什么英雄,并且玩的很顺风,突然不小心有个失误被集火了,如果能瞬间换个复活甲,等待队友的输出,可能就对局势有至关重要的影响;或者在最后守水晶或者冲水晶时需要自己用复活甲换对面的输出。
换指定装的核心难题,最主要的难题是要卖掉哪件装备。
大多数情况下,最合适的选择,是卖掉鞋子,因为太便宜了,后期的附属属性就不高;其次是最贵的装备,否则可能买不起指定装。
由于格子是顺序装装备的,因此实际上,我们不太清楚要卖的装备一定在哪个格子里。所以市面上有比如说预先设置好卖掉第六个格子然后买新装备的这种,我认为必要性不高。个人认为,换指定装最佳的方式,还是在和平时提前选好要卖的装备与要买的装备,然后在战时直接使用一键换装。
iOS 秒换装实现之语音控制(Voice Control)实现自定义手势
在 iOS 平台上,目前最适合小白用户使用的官方办法,是基于语音控制。
所谓的语音控制,倒不是各种 AI 或者 siri 之类的智能语音控制,而是 iOS 自带的辅助功能里的语音控制,用户可以自己自定义一条语音指令,并未其搭配上手机要执行的输入或者点击动作。
于是我可以指定一条比如“乌拉”,然后设置其的动作为在屏幕上依次点击四个点(一键换装)的位置。保存之后,就可以通过大喊一声“乌拉”去触发它。
听起来很酷,但这种办法有几个缺点。
第一个缺点,是在配置这个点击动作时,它展示的是一个纯白的界面,实际上你不知道自己点的位置对应游戏里的哪个点。
这几乎只能从硬件上解决:比如我撕了几块小胶带,对照着截图提前贴在屏幕上的对应位置上,有些 B 站视频是用了记号笔,我没有这种可以画在贴膜上的记号笔。
第二个缺点,是一键换装的点击位置比较靠近边缘(购买键、关闭键),而 iOS 的手势定制时则必须先点击下方的“隐藏控制”,然后才能完整录入四个点的位置,并等待十秒后才能退出(虽然不影响后续操作,但每次都要运行 10 秒的脚本确实不够理想,从完美主义角度来说)。而最关键的就是即使屏幕上有四个标识好的坐标,手指去按时,也很难按照顺序按到最快,毕竟人手始终有反应速度的问题。因此理论上可能至少要 0.5 秒,实际在 1 秒左右。
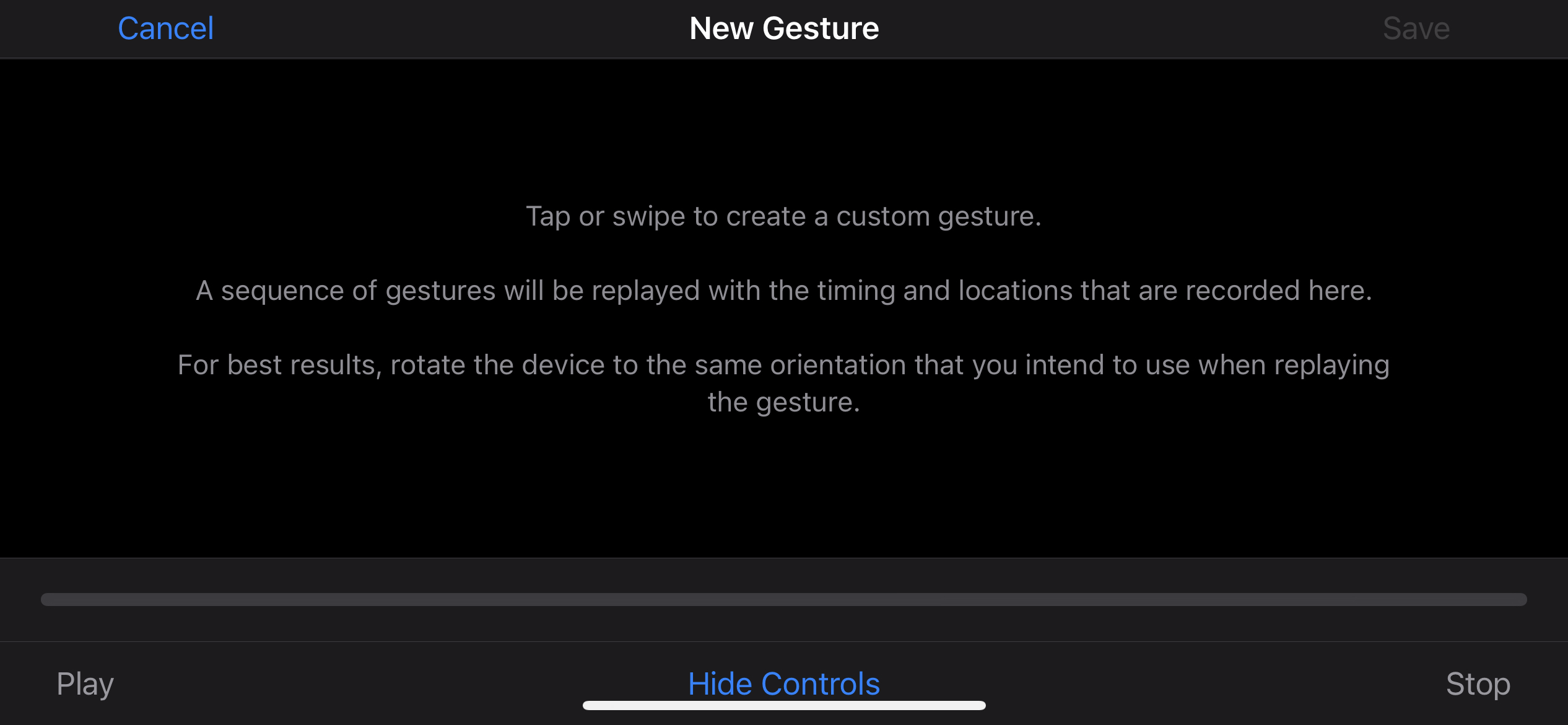
如果前两个缺点还只是可以克服的小问题,那么第三个缺点就无法忽视了,那就是启动延时。由于 iOS 的语音控制,需要经过一套算法去识别你有没有喊“乌拉”这个词,因此需要时间,而这个时间,在恒定的一秒左右。所以通过这个办法,至少我测试下来,当我从喊乌拉时到换装完成,实际耗时要在 2.5 秒左右。这个时间,说实话,很不可以接受。
比如我玩诸葛时有套“富贵险中求”的连招就是“2 冲刺+1+3+金身+2 追击或者撤退”,一套操作都是几乎瞬间完成的,此时如果我们在用完金身后再语音控制进行换装,那基本上是不现实了。
考虑到这种情况,我后来想了个办法,就是提前喊口令。因为在喊完口令后,要大概一秒才会触发换装,所以我就在准备冲锋时先喊“乌拉”,再按“2+1+3+金身”,此时等待换装完成,然后再后续操作。
这听起来有点奇怪,非常奇怪,有种蒙太奇的感觉,但它确实是某些场景的有效的解决方案。
哦对了,最后,说一下语音控制中英文的问题,由于中文指令至少要四个字起步,因此建议配置英文指令,可以很简单的比如说用“f**k”完成,乌拉不属于英文,但你可以自己配置“wula”的词汇。再者,中文的识别难度肯定比英文大,苹果毕竟是美国的公司,用英文都已经 1 秒延迟了,别说中文了。
iOS 秒换装实现之越狱、第三方应用
刚刚讲了用苹果官方的语音控制来实现自定义手势以完成一键换装的办法,缺点最主要的是执行时的延迟。
那有没有其他的软件可以帮助我们更快的反应呢?
有。但如果我们不越狱的话,几乎没有可用的,比如按键精灵之类。
反正病毒风险很高,也基本都要收费。
越狱是不需要收费的,但越狱代价是很高的,普通小白肯定没必要考虑,不然手机就不保修了。
另一种办法是通过外设实现。
秒换装实现之基于外设硬件
就我所了解到的,国内至少有飞智和北通两家公司在做基于王者荣耀、吃鸡等游戏的外设生态开发,用户只需要购买他们的手柄接上,就能在软件里自定义每个按键的宏动作,从而实现一键换装、英雄连招等操作了。
我实际体验过北通 H2 和飞智黄蜂 2 两款外设,首先值得肯定的是他们的外设确实是有效的,完全没有上述语音控制的延时问题了。
但接着个手柄(单手柄或者双手柄)玩王者之类的游戏,还是有点奇怪,因为实际没有完全脱离屏幕,比如比较畅销的黄蜂 2 左手手柄,确实右手的放技能还得在屏幕上比较方便,毕竟每个技能都要摇动,不是一般手柄能够实现的。一般的游戏手柄只有两个摇杆。
但也有不少问题。北通 H2 的硬件连接、手感、颜值上要逊色于飞智黄蜂 2(当然北通价格也更便宜点),此处暂时不展开对北通 H2 的评价了,是我去年体验的,不太记得了。飞智黄蜂 2 最近体验了一下,说一下它的优缺点。
首先是优点吧,颜值、做工(据说是日本摇杆)、连接、软件上整体做的都非常不错,体验很好。
缺点的话,苹果的横屏游戏默认是顺时针旋转 90 度,也就是屏幕顶部是左边。而苹果 13 的摄像头是凸起的,此时如果接黄蜂飞智 2 的左手手柄,会发现不够稳定(如果是接右边则非常贴合),当然由于上下还是能够用力压住,所以还是能用,只是摄像头那部分被压着,感觉不太好。
这里完全不建议用户把手机开启自动旋转后,逆时针转 90 度后搭配飞智黄蜂 2 玩,否则会发现按键位置完全反了,没法用。飞智官方是推荐大家关闭旋转使用的。但我实际体验下来,通过先逆时针旋转 90 度然后锁定方向后,再去飞智里重新配置(进去再保存再出来,不用更改),其实也能用,只是偶尔会转来转去,这点上是飞智自己的软件没优化到位,或者不愿意担风险,因为硬件操控屏幕的原理是物理坐标点固定的,旋转屏幕后坐标点没变,但游戏中却变了。飞智毕竟是通过软件提前固定好坐标点,所以如果不关闭自动旋转,用户在游戏中旋转手机后则必然出现问题。
不过对于我来说,还有几个小问题。
首先是性能过剩,飞智黄蜂 2 配备了摇杆、A 键、B 键、LT 键、LB 键、扳机键,键位对我来说太多了,我其实只要一个键就可以了,这款手柄更适合玩吃鸡。更适合我的其实是飞智的另一款手柄:壹柄,它只有一个摇杆和按键。
另一个黄蜂 2 的问题,就是摇杆的位置太偏上了,导致我的手型不是特别舒服,不像直接在屏幕上玩,虎口的角度大概在 45 度,用飞智直接变成 5 度了。
综上这些考虑,我还是把黄蜂 2 退掉了,毕竟那个价格给我的体验达不到期望,性能也绝对过剩。
壹柄的话后续我也没有继续考虑,因为我在研究飞智的软件时,同步研究了不越狱情况下对 iOS 自动化的实现办法,而这最终成功了,那就是大名鼎鼎的 wda:WebDriverAgent。
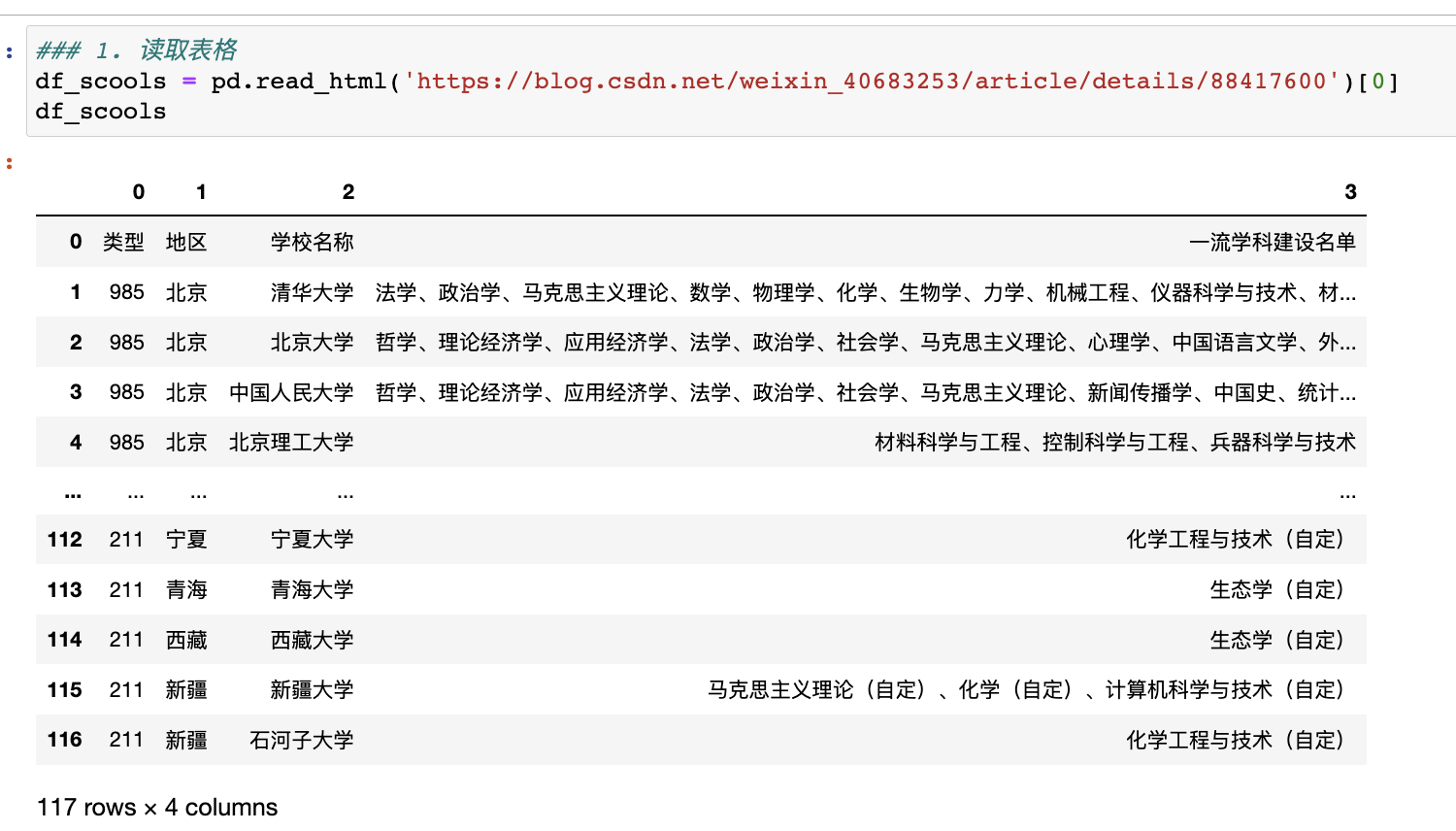
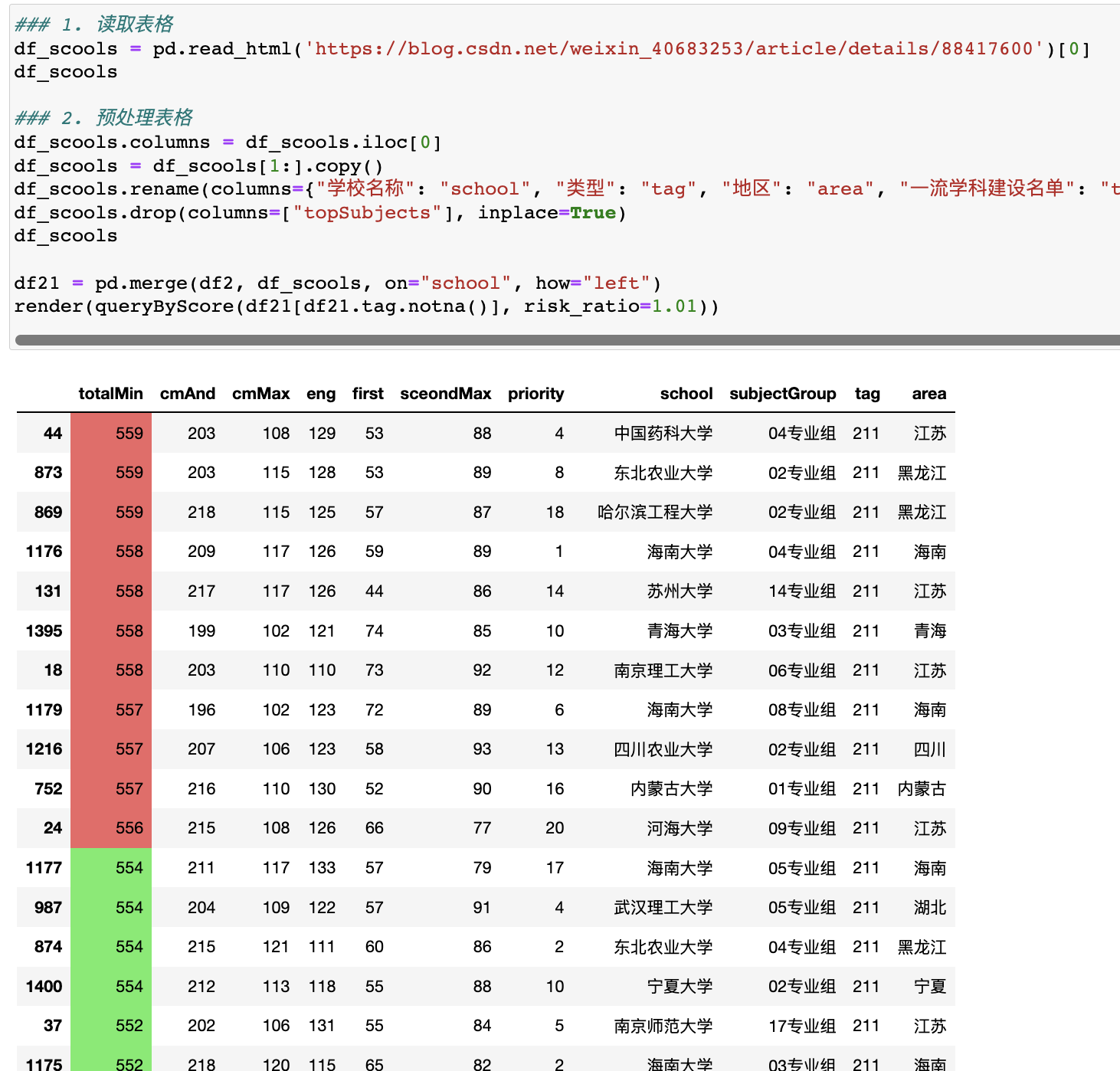
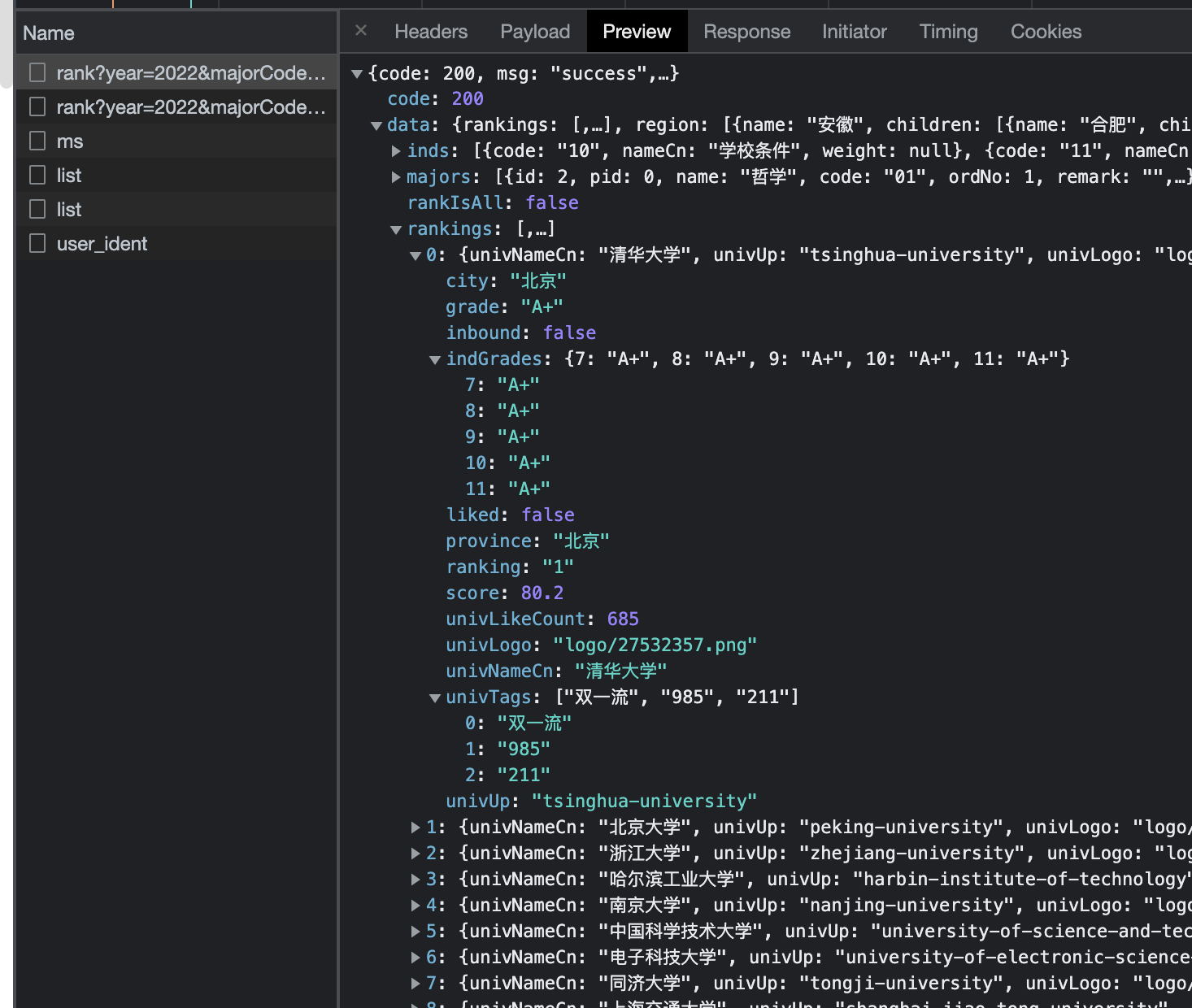
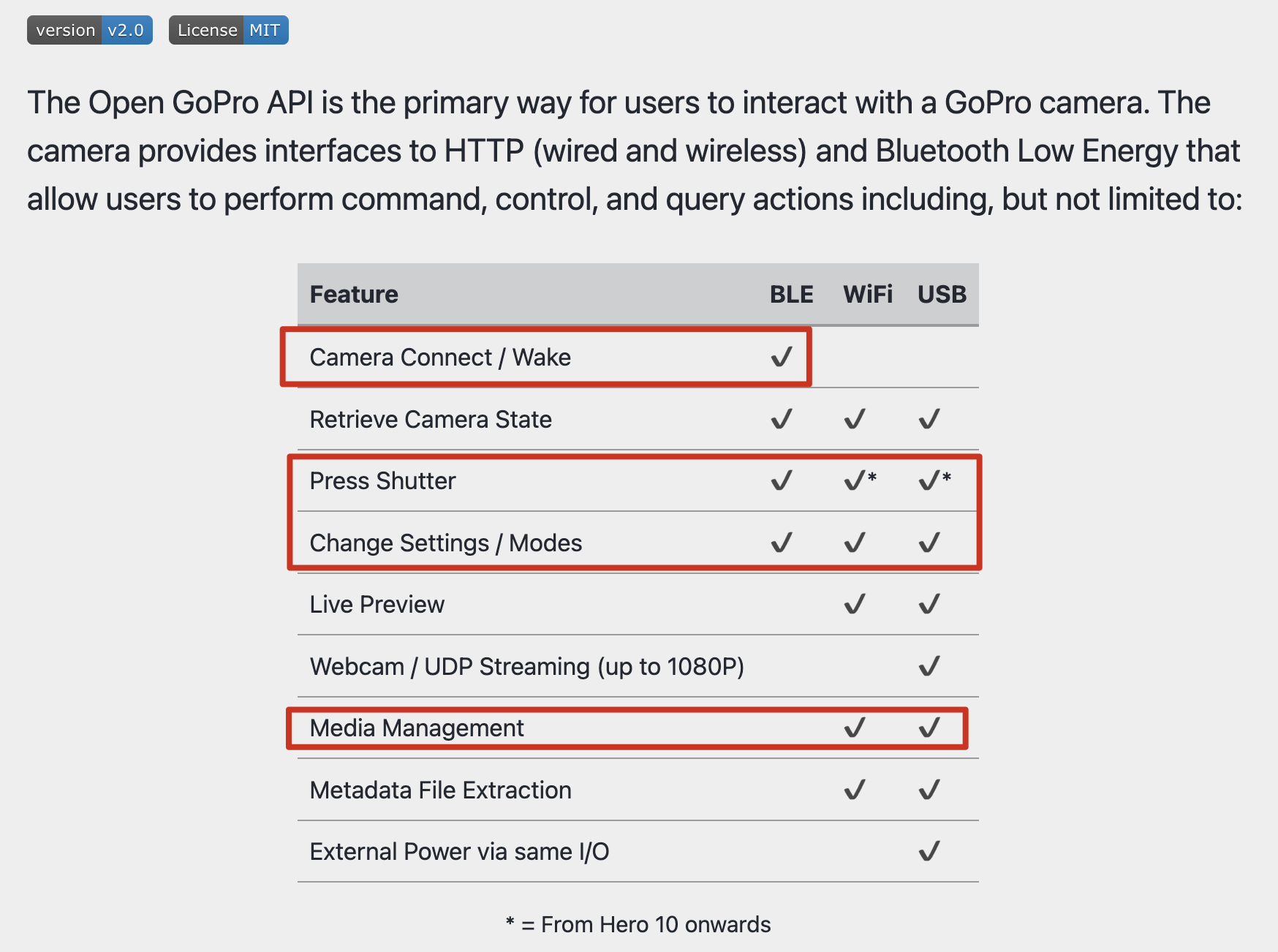
iOS 秒换装实现之基于 iOS 自动化:facebook-wda(WebDriverAgent)
wda 是什么?从名字来看:WebDriverAgent,网页驱动代理,这个对于我(一名专业的爬虫工程师)来说太熟悉不过了,我们平常用的 selenium 自动化框架其实背后都需要一个 driver,比如 phantom、google 的 chromedriver 或者 firefox 的 geckodriver。
那 wda 的作用就是把整个手机系统的 ui 操作,集中到这个 wda 身上,通过 wda 向下调用系统的 ui 操作指令,从而完成自动化。
在 iOS 平台上,这个系统 ui 操作指令的框架,是苹果自带的UiAutomation(已废弃)和XCTest.framwork。
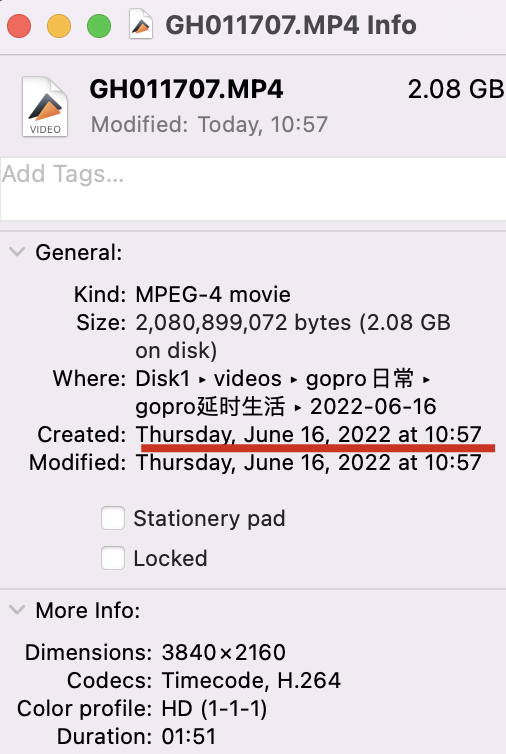
在我配置 wda 的过程中,经历了漫长而又痛苦的调试过程,一开始我是直接用 facebook 官方的WebDriverAgent进行配置的,结果各种 bug,主要是我的 xcode、我的手机系统(iOS15)太新了。
爬坑的过程可以参考:- WebDriverAgent 重签名爬坑记 - 温一壶清酒 - 博客园
当时就是卡在了第二步,百般搜索都得不到解决办法,结果竟然找到一个国人把四步都走完了。
但尽管如此,基于 facebook 的这个 wda,我最终还是有一步没有搞定,那就是inspector不出截屏图片,我看了原因,还是有一句代码没过,所以这个代码确实太老了。
最终,我选择了文章里说的方法二,也就是基于 appium 里面的 wda,一下就成功了,果然代码还是得用新的。
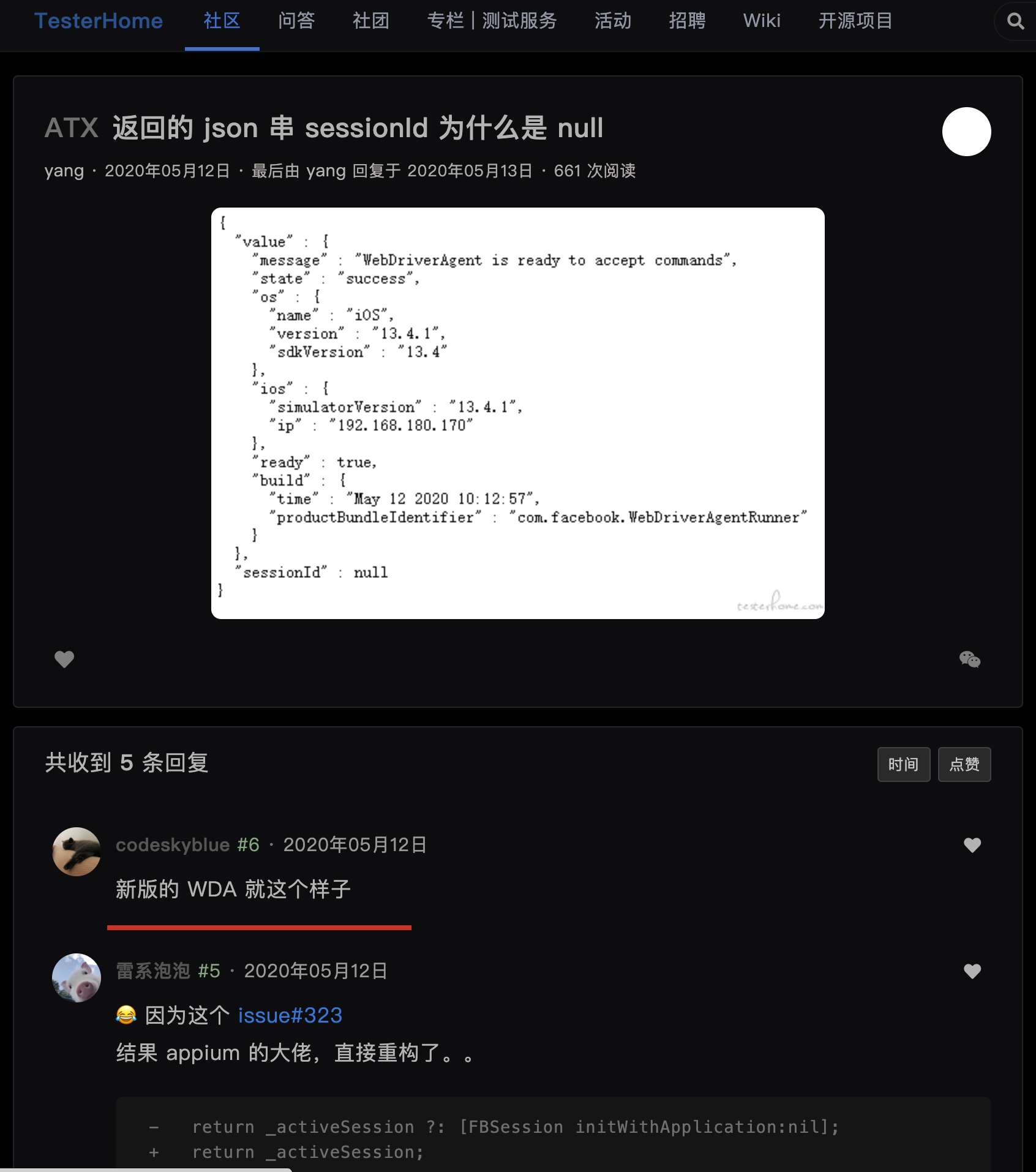
新的 wda 里也没有inspector,而且session默认返回null了,我以为又是我的操作的问题,后来在 返回的 json 串 sessionId 为什么是 null · TesterHome确认了是新的版本设计。
最后一切 ok 之后,使用facebook-wda的 python 客户端进行连接,果然成功了,然后就可以通过代码控制屏幕的触摸手势了,一切都非常丝滑。
不过使用WebDriverAgent也有一些问题,最大的问题是由于底层使用了 iOS 自带的 Test 框架,所以会有两行字“Automation Running, Hold...”在屏幕上随机浮动,有时会长时间不提示,有时就会一直都在,虽然是层“Overlay”半透明的,但是很烦,这个没法去除。
另外有一个问题是屏幕没动作每隔两三秒就会自动变暗,于是我在执行脚本的时候启动了两个线程,一个线程捕获键盘动作执行脚本,另一个线程每隔 2 秒钟点击一下屏幕上的(0, 0)处坐标,保持屏幕常量,实测有效。
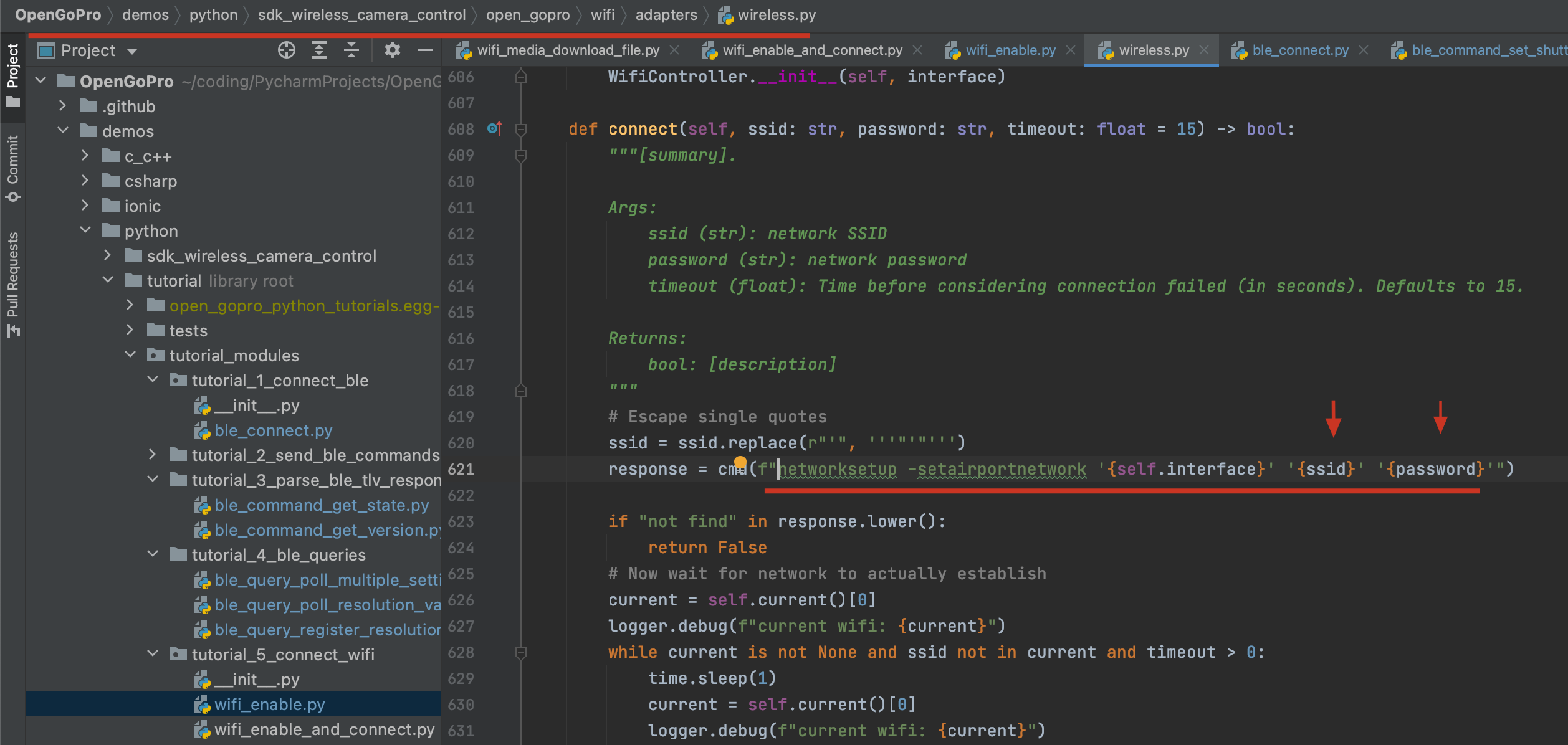
以下是现成的执行代码脚本:
import wda
import time
wda.HTTP_TIMEOUT = 5.0
DURATION = 0.01
IS_RUNNING = False
url = "http://localhost:8100"
session_id = '00008110-000634163E9B801E'
c = wda.USBClient()
print(c.status())
c.wait_ready(timeout=300)
CHOOSE_Y = 0.8837606837606837
CHOOSE_1 = (0.34360189573459715,
CHOOSE_Y)
CHOOSE_6 = (0.6994470774091627,
CHOOSE_Y)
CHOOSE_X_INTERVAL = 0.0711690363349131
IS_SHOPPING_OPEN = False
def open_shop():
global IS_SHOPPING_OPEN
if not IS_SHOPPING_OPEN:
print("打开商店")
IS_SHOPPING_OPEN = True
c.click(0.06872037914691943,
0.4111111111111111, DURATION)
def sell():
print("卖出装备")
c.click(0.8270142180094787,
0.8017094017094017, DURATION)
def buy():
print("购买装备(在商店中)")
c.click(0.8270142180094787,
0.9017094017094017, DURATION)
def close_shop():
global IS_SHOPPING_OPEN
if IS_SHOPPING_OPEN:
IS_SHOPPING_OPEN = False
print("关闭商店")
c.click(0.8609794628751974,
0.08034188034188035, DURATION)
def buy_first_recommended():
print("购买第一件推荐装备")
c.click(0.13361769352290679,
0.40615384615384615, DURATION)
def select_k_bought(i):
"""
选中第i个已买的装备
:param i: 从1到6
:return:
"""
print(f"选择第{i}格已买装备")
c.click(CHOOSE_1[0] + (i - 1) * CHOOSE_X_INTERVAL, CHOOSE_Y, DURATION)
def select_move():
print("筛选【移动】(鞋子)")
c.click(0.13230647709320695,
0.6068376068376068, DURATION)
def select_attacks():
print("筛选【攻击】")
open_shop()
c.click(0.12717219589257503,
0.30256410256410254, DURATION)
def select_defense():
print("筛选【防御】")
open_shop()
c.click(0.12717219589257503,
0.55056410256410254, DURATION)
def buy_mingdao():
"""
购买名刀
:return:
"""
print("购买名刀")
open_shop()
select_attacks()
c.swipe(500, 300, 500, 0, DURATION)
time.sleep(0.1)
c.click(0.45, 0.32, DURATION)
buy()
def buy_fuhuo():
"""
购买复活甲
:return:
"""
print("购买复活甲")
open_shop()
select_defense()
c.swipe(500, 300, 500, 0, DURATION)
time.sleep(0.1)
c.click(0.65, 0.18, DURATION)
buy()
def run_buy_fuhuo():
print(">>> 一键购买复活甲")
buy_fuhuo()
close_shop()
def run_buy_mingdao():
print(">>> 购买名刀")
buy_mingdao()
close_shop()
def run_one_switch_for_first_recommended():
"""
一键换预选装
:return:
"""
print(">>> 一键换装")
open_shop()
sell()
close_shop()
buy_first_recommended()
def run_one_clear():
"""
:return:
"""
print(">>> 清空装备")
open_shop()
for i in range(1, 7):
select_k_bought(i)
sell()
close_shop()
def run_one_buy_attacks():
"""
:return:
"""
print(">>> 购买推塔装")
def buy_gongsuqiaing():
"""
速击之枪
:return:
"""
c.click(0.42101105845181674,
0.8008547008547009, DURATION)
buy()
def buy_fengbaojujian():
"""
风暴巨剑
:return:
"""
c.click(0.42338072669826227,
0.1811965811965812, DURATION)
buy()
open_shop()
select_move()
c.click(0.42101105845181674,
0.8257264957264957, DURATION)
buy()
select_attacks()
buy_gongsuqiaing()
buy_gongsuqiaing()
buy_fengbaojujian()
buy_fengbaojujian()
close_shop()
def process_keep_awake():
while True:
c.tap(0, 0)
time.sleep(2)
def process_monitor_input():
import keyboard
while True:
if keyboard.is_pressed('ESC'):
return
elif keyboard.is_pressed(' '):
run_one_switch_for_first_recommended()
elif keyboard.is_pressed("f"):
run_buy_fuhuo()
elif keyboard.is_pressed("m"):
run_buy_mingdao()
elif keyboard.is_pressed("q"):
run_one_clear()
elif keyboard.is_pressed("g"):
run_one_buy_attacks()
if __name__ == '__main__':
from threading import Thread
p1 = Thread(target=process_monitor_input)
p2 = Thread(target=process_keep_awake, daemon=True)
p1.start()
p2.start()
p1.join()
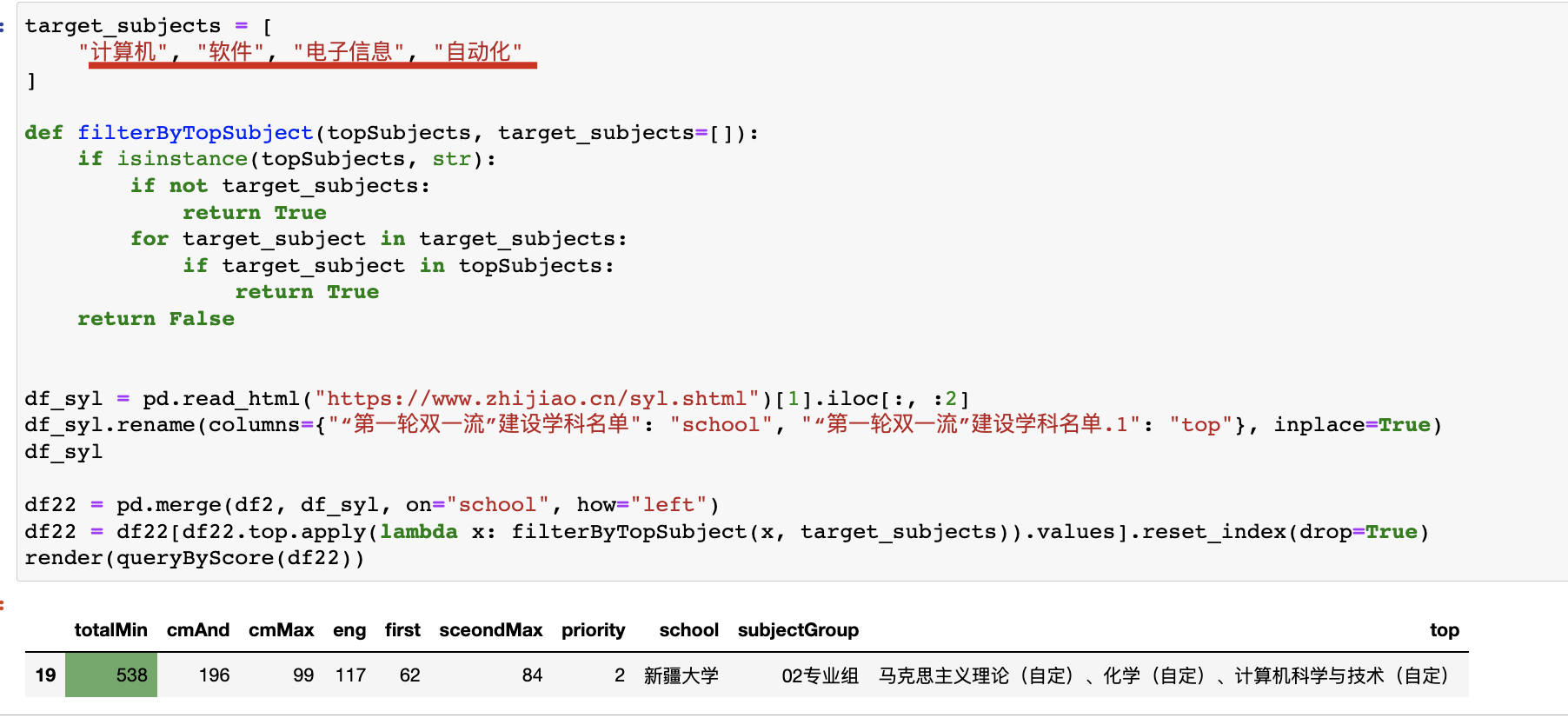
这些硬编码的坐标也需要通过一个脚本获取,我是基于 opencv 实现的:
"""
ref:
- [Displaying the coordinates of the points clicked on the image using Python-OpenCV - GeeksforGeeks](https://www.geeksforgeeks.org/displaying-the-coordinates-of-the-points-clicked-on-the-image-using-python-opencv/)
- [How to draw Chinese text on the image using `cv2.putText`correctly? (Python+OpenCV) - Stack Overflow](https://stackoverflow.com/questions/50854235/how-to-draw-chinese-text-on-the-image-using-cv2-puttextcorrectly-pythonopen)
"""
import cv2
import jstyleson
json = jstyleson
coors = []
def click_event(event, x, y, flags, params):
if event == cv2.EVENT_LBUTTONDOWN:
print(x, ' ', y)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, str(x) + ',' +
str(y), (x, y), font,
1, (0, 255, 0), 3)
coors.append((x / w, y / h))
cv2.imshow('image', img)
if event == cv2.EVENT_RBUTTONDOWN:
print(x, ' ', y)
font = cv2.FONT_HERSHEY_SIMPLEX
b = img[y, x, 0]
g = img[y, x, 1]
r = img[y, x, 2]
cv2.putText(img, str(b) + ',' +
str(g) + ',' + str(r),
(x, y), font, 1,
(255, 255, 0), 2)
cv2.imshow('image', img)
if __name__ == "__main__":
fn = input("脚本名:")
img = cv2.imread('assets/攻击.png', 1)
h, w, channels = img.shape
print(f"w: {w}, h: {h}")
cv2.imshow('image', img)
cv2.setMouseCallback('image', click_event)
cv2.waitKey(0)
cv2.destroyAllWindows()
json.dump(coors, open(f"{fn}.json", "w"), indent=2)
UI 自动化的缺点(行走中的触控集成问题)
最后说说 UI 自动化的缺点。
多点触控集成
首先是影响可行性的一个问题:多点触控集成。
这个问题在我去年做安卓触控开发的时候就发现了,为此我当时写了一个触控集成中心,当做系统触控事件的代理人、中间人,实测有效,但有点 bug,由于时间有限最后也没有去修复。
这个问题到底是啥呢?那就是安卓与苹果系统的触控事件单元,不是基于手指的,而是基于时间戳的。
啥意思呢?
意思就是,当我手指在屏幕上点击一个点时,系统报的是一个单指点击的动作;而如果是两根手指点击了两个点时,系统报的是一个双指点击的动作。那么问题来了,当我在游戏中使用左手控制方向盘移动时,系统报的是一个单指按压移动的动作;此时如果我用自动化控制脚本再发送一个点击动作,则不可行,因为此时应该是一个双指动作,但现在缺少那么一个中枢告诉系统,我现在是双指了,因为屏幕是屏幕,脚本是脚本,如果用脚本,那么手指在屏幕上最好别动。否则脚本在动,手指也在动,系统就会犯迷糊,这是最大的问题。
我当时做的就是首先监控屏幕上的手指,把它拦截;同时监控外设的输出,也把它拦截,然后把两个根据安卓的规则再封装,再往下传,这是可行的。但我们的 iOS 平台上的 wda,我目测下来是不行的。
所以平常我可以边移动,边用另一根手指打开商店进行换装。
但现在,使用脚本,你只能移动停止后,再启动脚本换装完成,然后再恢复移动,中间一定不要碰屏幕,否则轻则导致换装失败,重则脚本直接挂掉,因为会让 iOS 觉得这个触控事件输入有问题。
好在,这个问题其实不大,我之前用一开始的脚本录了一个视频,这里面可以看到换装的时间还比较长的。
【视频:一键换装】
后来考虑到了这个问题,不能长,所以我修改了程序里面每个按键的默认时长,都改为了 0.01 秒完成按键动作,然后换装就直接飞快,这绝对不是人手可以点出来的速度,但它就是有效的。
封号的风险
那点这么快,会不会有封号风险?
哈哈哈,其实不会,以我多年的经验,可以肯定的说,首先我们基于的是苹果自带的自动化控制框架,因此每个点击动作都是有苹果系统官方背书的,一个处于应用层的游戏,只有老老实实接受系统输入的份。
并且,我们的换装,基本上只占游戏全程极其小的一部分,有时候甚至一局都没有一次换装,因此即使 TX 的反作弊数据分析部分再牛掰,怕也是无法找到你自动化的蛛丝马迹。尤其是如果我再在程序里加入随机抖动算法的话,尽管显然没那个必要。
需要 USB 接入
我非常希望能像安卓平台上的 adb 一样,先用有线接上,再断开用无线。
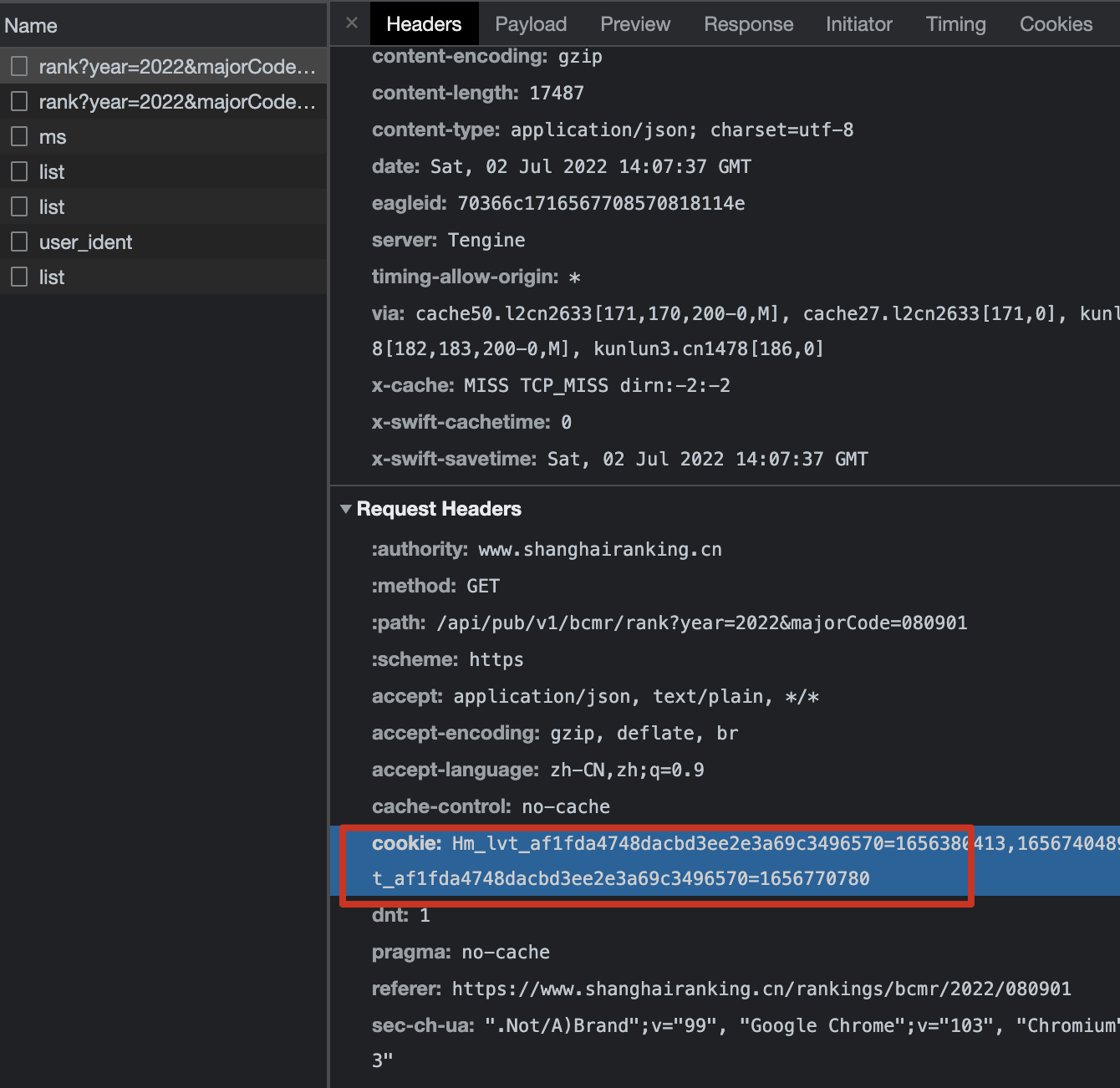
我看到facebook-wda里面提供了无线连接的方式,但很可惜我没能实现,无论是使用iproxy端口转发的操作还是啥,我都必须有线连着脚本才能正常运行,这让我打游戏时的感觉很怪。
因为其实我已经接了一个散热背夹,没错,其实比起自动化脚本,散热才是更更更重要的关注点,否则这个夏天,一局还没打完就已经手机发热然后掉帧、烫手,然后你就输了。
推荐这款,我用下来感觉还不错:
不过由于最近已经不玩游戏了,所以退了所有的游戏外设。
要说为啥,因为找到了新的乐趣来源,那就是这今年一直要做的另一件事:读尽世间书,阅尽天下片!
毕竟游戏玩的再好,也只是一盘一盘的重复,但人生却是无止尽的向前。我们,未来再见!



【音乐:Saturn】