- 语音转写市场概览
- 网易见外的缺点
- FCPX 不支持网易见外导出的 srt 字幕文件
- 网易见外的转写结果需要手动进行长度切割
- 网易见外只支持后期文本替换,而不支持前期预设词库
- 网易见外不支持基于鼠标点击的文本位置智能跳转语音并播放
- 讯飞转写
- 讯飞服务价格
- 讯飞语音转写控制台
- 讯飞语音转写的使用
- 讯飞语音转写使用分词
- 讯飞语音转写程序
- 基于 Automator 实现右键语音文件后台自动转写
语音转写市场概览
目前国内中文语音转文字,做的最好的应该是科大讯飞(可惜要付费):
所以其实很多 UP 主用的是网易见外之类的免费转写产品。
其他转写平台还有,比如:
网易见外的缺点
我实际体验下来,网易见外还是不太能满足我的需求的,主要如下:
FCPX 不支持网易见外导出的 srt 字幕文件
这个我之前就了解了一下,发现大家都是用一些第三方软件再将网易见外的 srt 转换成另一种 srt,不禁引起了我的好奇,到底为啥网易见外的 srt 不支持 fcpx 导入。
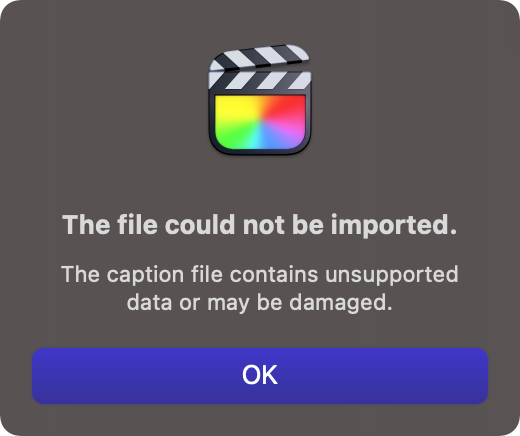
我对比了讯飞转写和网易见外的 srt 文件,发现两者的唯一区别就在于编序下标不同:网易见外从 0 开始标记,而讯飞转写从 1 开始:
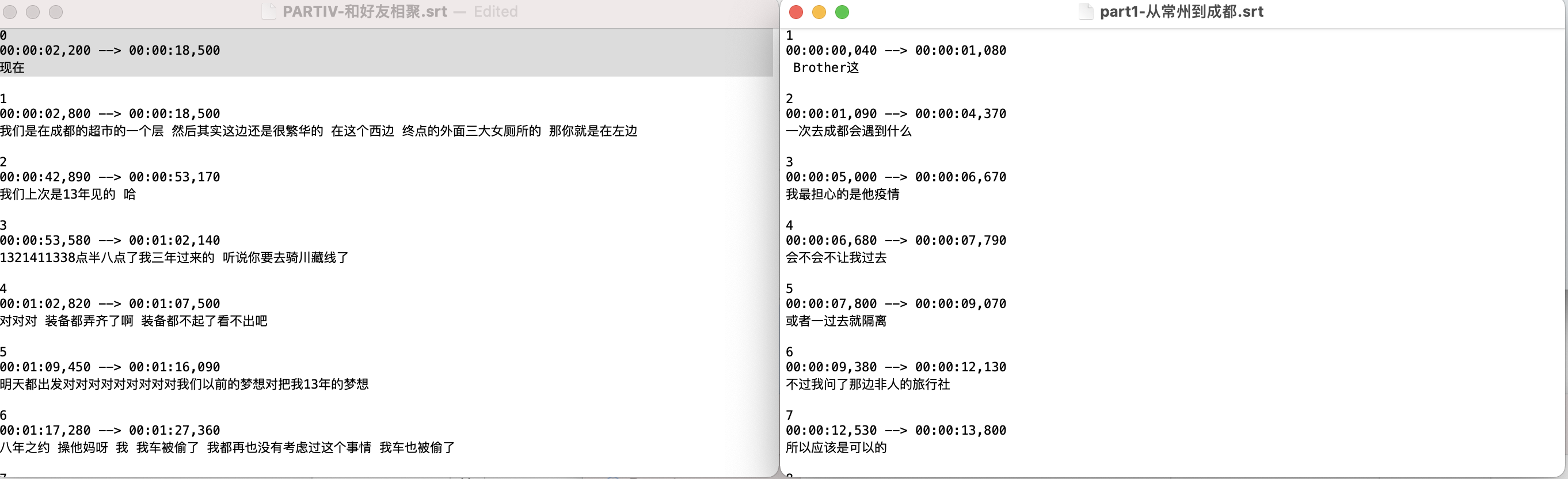
由此大胆猜测:FCPX 对 srt 文件的硬性要求就是从 1 开始编码!
于是我将网易见外的第 0 号编码对应的字幕内容去掉,重新导入 FCPX,结果成功了,此即证实了我的猜想。
了解了原因之后,这个问题就变得不那么恐怖了,随便用什么脚本语言把网易见外的 srt 文件里的序号全部加 1,或者干脆把第一条去掉即可。不是什么难事。
网易见外的转写结果需要手动进行长度切割
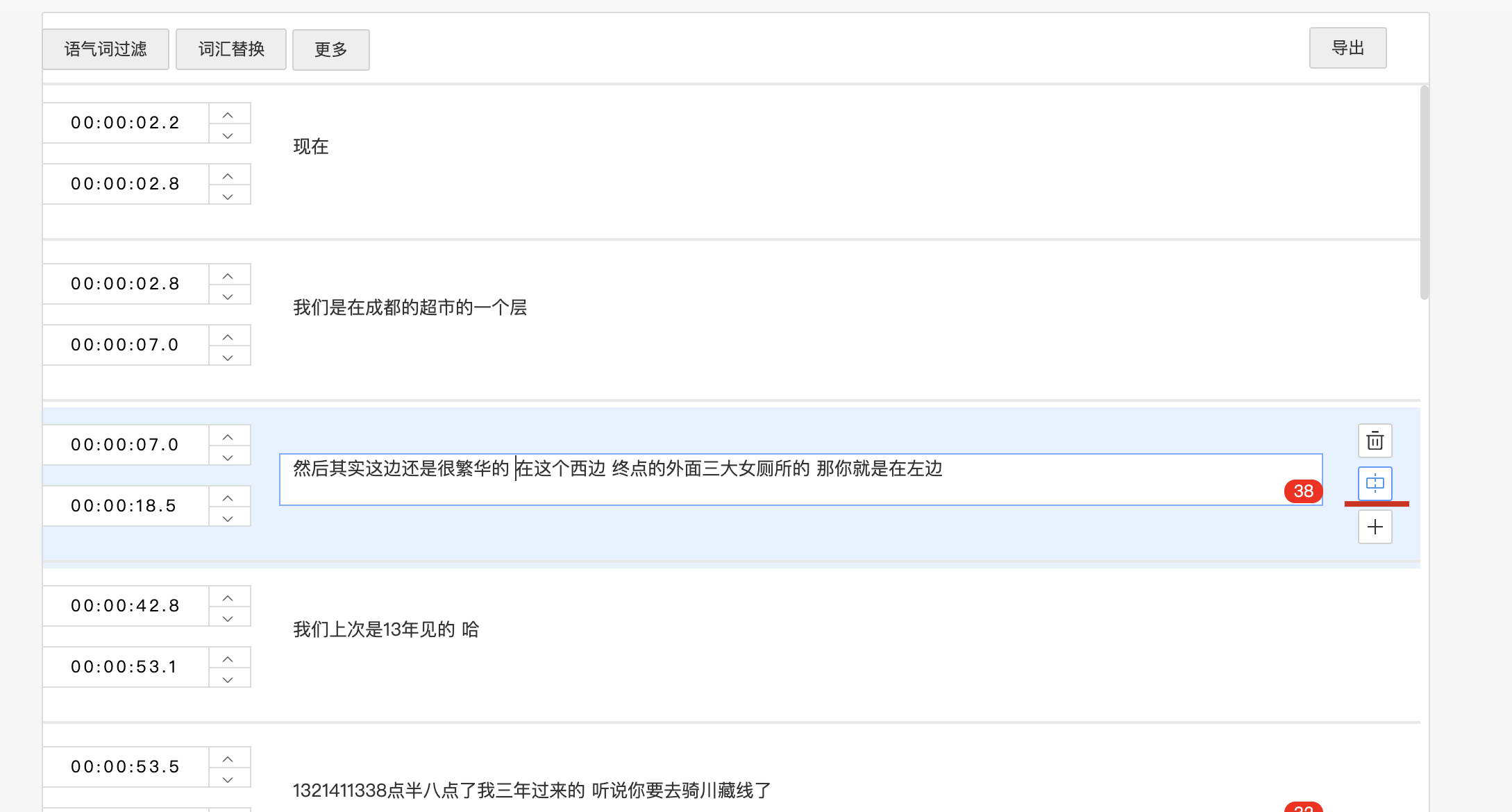
网易见外的默认转写字幕长度是偏长的。这其实可以理解,因为长一点有助于基于上下文分析提高转写的准确度。
但问题就在于,想把分好的每句字幕再切小一点,则需要手动的在网页上点击分隔按钮一个个地调整,这个工作量就变得无法接受了。
网易见外只支持后期文本替换,而不支持前期预设词库
对于学过机器学习的程序员或者用过jieba分词之类开源代码库的人都知道,预设词库在文本分析相关领域是非常重要的,显著影响算法识别的准确度和使用体验。
然而网易见外是不支持转写之前预设词库,只可以转完之后在页面点击文本替换,由此可见网易转写的机器学习模型(如果有的话)比较低级,它只有通用的一个,不支持用户自己输入词库进行模型微调。
网易见外不支持基于鼠标点击的文本位置智能跳转语音并播放
这个是讯飞转写的一个很友好的功能,并且在技术是线上我认为也不是很难的一件事,但很可惜,网易见外也未能把这个用户体验做起来。
基于以上原因,我认为网易见外是远未达到我对一个智能转写软件平台的目标要求的。
讯飞转写
讯飞服务价格
如果没有开通过讯飞的服务,可以申请免费使用。不过有一定要求,比如企业用户需要提交工商执照相关信息,而个人用户,看声明貌似要 19 年的新用户……反正我是不符合了(我以前应该用过)。

讯飞语音转写控制台
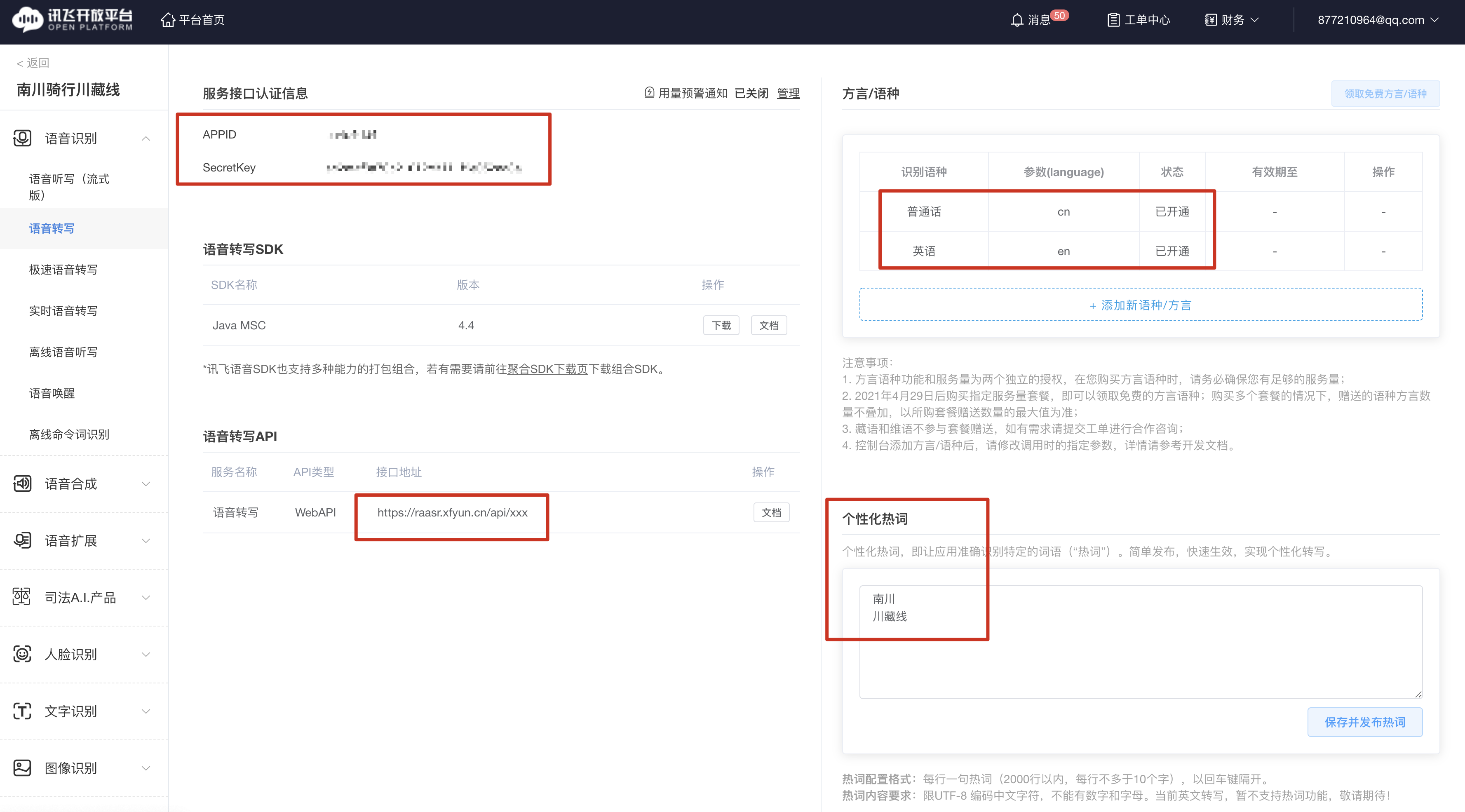
在控制台,可以查看自己所购买的讯飞服务详情,最主要的就是确认自己购买的是“讯飞转写”的服务,然后至少要支持中英文转写,最后在个性化热词里可以加入自己的特殊词库(用于提高准确率,非常有用)。
讯飞语音转写的使用
可以使用讯飞语音转写的 api,在该页可以下载各大语音(例如 python)的 demo:语音转写 API 文档 | 讯飞开放平台文档中心
建议直接对着 demo 改,否则从 0 到 1 写会很麻烦,因为要很多加密相关参数。
讯飞语音转写使用分词
在 /prepare 接口的参数中如果加上 has_participle = true,则会返回带每个词语识别的结果。
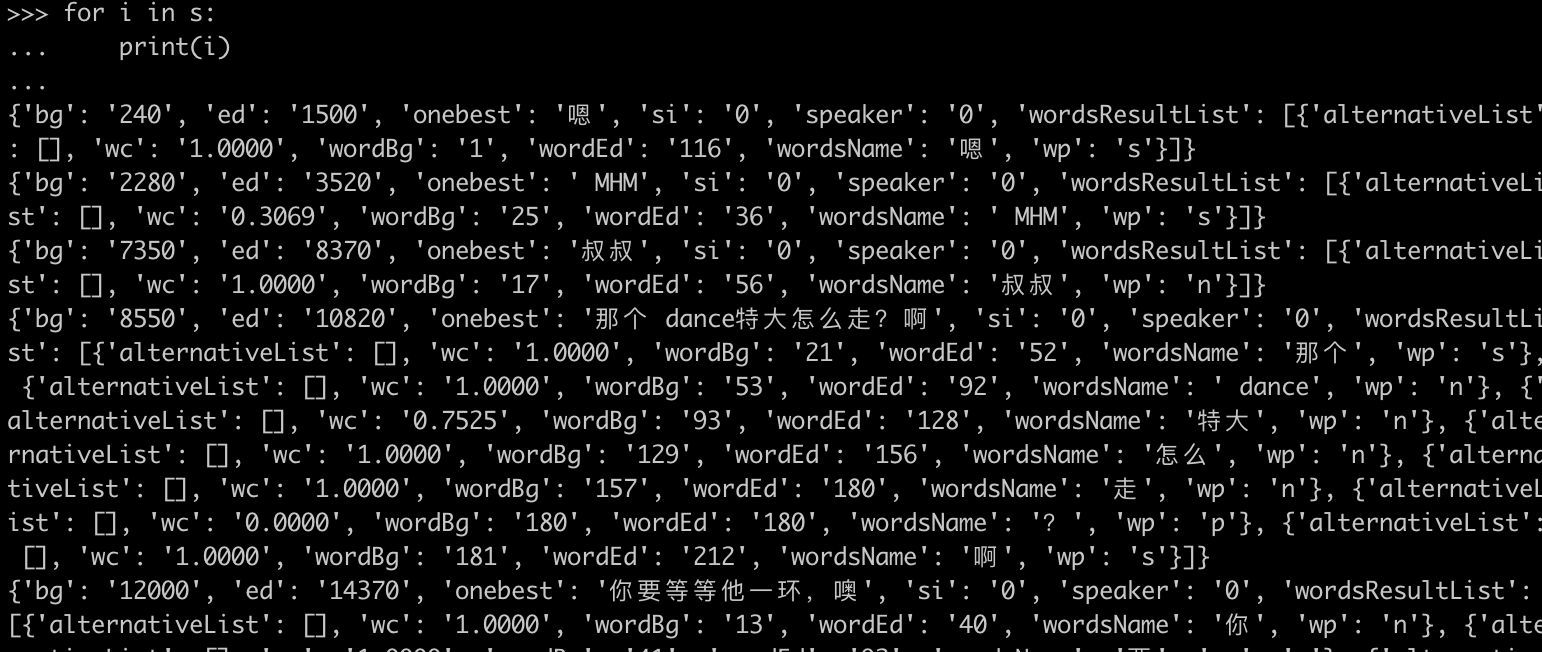
不过深入去使用词级别的解析结果也是一件不太容易的事情,因为需要我们自己去处理断句的问题。比如说要通过'wordsName': ','去判别是个断句。
基于这个角度来看,网易见外不支持按长度的智能分句,似乎也变得不是那么不能接受了。
但尽管如此,讯飞的结果依旧要比网易见外好很多。
讯飞语音转写程序
已同步在个人仓库:https://github.com/MarkShawn2020/mark_keeps_learning/blob/master/mark_scripts/voice2srt/main.py
具体脚本内容如下:
# -*- coding: utf-8 -*-
#
# author: yanmeng2, xunfei api relative
# author: markshawn2020, xunfei result to srt-format file, 2022-05-13
# config: https://console.xfyun.cn/services/lfasr
# doc: https://www.xfyun.cn/doc/asr/lfasr/API.html
#
import base64
import hashlib
import hmac
import json
import os
import sys
import time
import requests
lfasr_host = 'http://raasr.xfyun.cn/api'
# 请求的接口名
api_prepare = '/prepare'
api_upload = '/upload'
api_merge = '/merge'
api_get_progress = '/getProgress'
api_get_result = '/getResult'
# 文件分片大小10M
file_piece_sice = 10485760
# ——————————————————转写可配置参数————————————————
# 参数可在官网界面(https://doc.xfyun.cn/rest_api/%E8%AF%AD%E9%9F%B3%E8%BD%AC%E5%86%99.html)查看,根据需求可自行在gene_params方法里添加修改
# 转写类型
lfasr_type = 0
# 是否开启分词
has_participle = 'false'
has_seperate = 'true'
# 多候选词个数
max_alternatives = 0
# 子用户标识
suid = ''
N = 10 # 每隔N秒获取一次进度
class SliceIdGenerator:
"""slice id生成器"""
def __init__(self):
self.__ch = 'aaaaaaaaa`'
def getNextSliceId(self):
ch = self.__ch
j = len(ch) - 1
while j >= 0:
cj = ch[j]
if cj != 'z':
ch = ch[:j] + chr(ord(cj) + 1) + ch[j + 1:]
break
else:
ch = ch[:j] + 'a' + ch[j + 1:]
j = j - 1
self.__ch = ch
return self.__ch
# -------------------- 从讯飞结果到srt的转换函数 -----------------
def time2stamp(s):
"""
将整数时间(毫秒)转化为srt的时间戳,即 HH:MM:SS,mmm
:param s:
:return:
"""
mmm = s % 1000
s //= 1000
SS = s % 60
s //= 60
MM = s % 60
s //= 60
HH = s
return f"{HH:02}:{MM:02}:{SS:02},{mmm:03}"
def pickle_srt_item(index: int, mm_start: int, mm_end: int, content: str):
"""
构建srt字幕文件的基本单元
:param index: 字幕序号,从1开始,手动创建
:param mm_start: 该字幕单元起始毫秒数
:param mm_end: 该字幕单元结束毫秒数
:param content: 该字幕单元的文本内容
:return:
"""
return f"{index}\n{time2stamp(mm_start)} --> {time2stamp(mm_end)}\n{content}\n"
def xunfei_json2srt(items):
"""
将讯飞转写的输出转成srt字幕文本内容
:param items:
:return:
"""
return "\n".join([pickle_srt_item(index + 1, int(item["bg"]), int(item["ed"]), item["onebest"])
for (index, item) in enumerate(items)])
class RequestApi(object):
def __init__(self, appid, secret_key, upload_file_path):
self._appid = appid
self._secret_key = secret_key
self._upload_file_path = upload_file_path
self.srt_fp = os.path.splitext(self._upload_file_path)[0] + ".srt"
print("--- initialized ---")
# 根据不同的apiname生成不同的参数,本示例中未使用全部参数您可在官网(https://doc.xfyun.cn/rest_api/%E8%AF%AD%E9%9F%B3%E8%BD%AC%E5%86%99.html)查看后选择适合业务场景的进行更换
def gene_params(self, apiname, taskid=None, slice_id=None):
appid = self._appid
secret_key = self._secret_key
upload_file_path = self._upload_file_path
ts = str(int(time.time()))
m2 = hashlib.md5()
m2.update((appid + ts).encode('utf-8'))
md5 = m2.hexdigest()
md5 = bytes(md5, encoding='utf-8')
# 以secret_key为key, 上面的md5为msg, 使用hashlib.sha1加密结果为signa
signa = hmac.new(secret_key.encode('utf-8'), md5, hashlib.sha1).digest()
signa = base64.b64encode(signa)
signa = str(signa, 'utf-8')
file_len = os.path.getsize(upload_file_path)
file_name = os.path.basename(upload_file_path)
param_dict = {}
if apiname == api_prepare:
# slice_num是指分片数量,如果您使用的音频都是较短音频也可以不分片,直接将slice_num指定为1即可
slice_num = int(file_len / file_piece_sice) + (0 if (file_len % file_piece_sice == 0) else 1)
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['file_len'] = str(file_len)
param_dict['file_name'] = file_name
param_dict['slice_num'] = str(slice_num)
elif apiname == api_upload:
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['task_id'] = taskid
param_dict['slice_id'] = slice_id
elif apiname == api_merge:
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['task_id'] = taskid
param_dict['file_name'] = file_name
elif apiname == api_get_progress or apiname == api_get_result:
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['task_id'] = taskid
return param_dict
# 请求和结果解析,结果中各个字段的含义可参考:https://doc.xfyun.cn/rest_api/%E8%AF%AD%E9%9F%B3%E8%BD%AC%E5%86%99.html
def gene_request(self, apiname, data, files=None, headers=None):
response = requests.post(lfasr_host + apiname, data=data, files=files, headers=headers)
result = json.loads(response.text)
if result["ok"] == 0:
print("{} success:".format(apiname) + str(result))
return result
else:
print("{} error:".format(apiname) + str(result))
exit(0)
return result
# 预处理
def prepare_request(self):
return self.gene_request(apiname=api_prepare,
data=self.gene_params(api_prepare))
# 上传
def upload_request(self, taskid, upload_file_path):
file_object = open(upload_file_path, 'rb')
try:
index = 1
sig = SliceIdGenerator()
while True:
content = file_object.read(file_piece_sice)
if not content or len(content) == 0:
break
files = {
"filename": self.gene_params(api_upload).get("slice_id"),
"content": content
}
response = self.gene_request(api_upload,
data=self.gene_params(api_upload, taskid=taskid,
slice_id=sig.getNextSliceId()),
files=files)
if response.get('ok') != 0:
# 上传分片失败
print('upload slice fail, response: ' + str(response))
return False
print('upload slice ' + str(index) + ' success')
index += 1
finally:
'file index:' + str(file_object.tell())
file_object.close()
return True
# 合并
def merge_request(self, taskid):
return self.gene_request(api_merge, data=self.gene_params(api_merge, taskid=taskid))
# 获取进度
def get_progress_request(self, taskid):
return self.gene_request(api_get_progress, data=self.gene_params(api_get_progress, taskid=taskid))
# 获取结果
def get_result_request(self, taskid):
return self.gene_request(api_get_result, data=self.gene_params(api_get_result, taskid=taskid))
def all_api_request(self):
# 1. 预处理
pre_result = self.prepare_request()
taskid = pre_result["data"]
# 2 . 分片上传
self.upload_request(taskid=taskid, upload_file_path=self._upload_file_path)
# 3 . 文件合并
self.merge_request(taskid=taskid)
# 4 . 获取任务进度
while True:
# 每隔N秒获取一次任务进度
progress = self.get_progress_request(taskid)
progress_dic = progress
if progress_dic['err_no'] != 0 and progress_dic['err_no'] != 26605:
print('task error: ' + progress_dic['failed'])
return
else:
data = progress_dic['data']
task_status = json.loads(data)
if task_status['status'] == 9:
print('task ' + taskid + ' finished')
break
print('The task ' + taskid + ' is in processing, task status: ' + str(data))
time.sleep(N) # 每次获取进度间隔N S
# 5 . 获取结果
srt_json = json.loads(self.get_result_request(taskid=taskid)["data"])
srt_str = xunfei_json2srt(srt_json)
with open(self.srt_fp, "w") as f:
f.write(srt_str)
print("has written converted result into path: " + self.srt_fp)
if __name__ == '__main__':
api = RequestApi(
appid=os.environ["XUNFEI_APP_ID"],
secret_key=os.environ["XUNFEI_APP_SK"],
upload_file_path=sys.argv[1]
)
api.all_api_request()
基于 Automator 实现右键语音文件后台自动转写
目前我们写的脚本,输入是一个文件路径,特别的,是指我们待转的音频文件,根据讯飞接口要求,对输入的文件有以下限制:
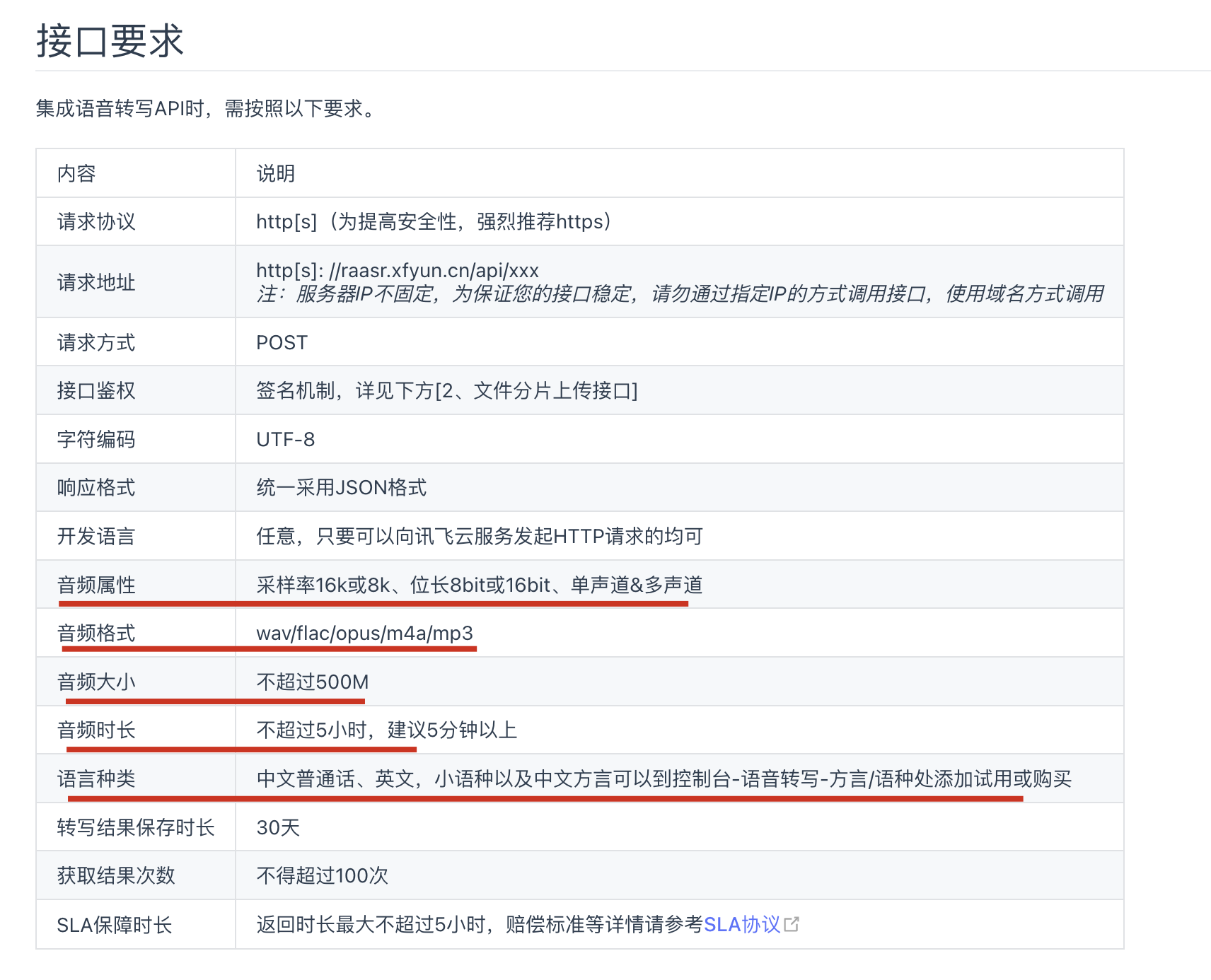
从音频格式来看,除了aac格式不支持,其他常用的例如mp3, wav, m4a都支持了,所以还是挺广泛的。
但是每次手动调用程序去转写一个音频文件,未免还是感觉有点麻烦,尤其是对于程序员来说。
比如现在我们转写一个音频文件,需要在命令行执行如下命令:
python3 ~/mark_keeps_learning/mark_scripts/voice2srt/main.py 目标音频文件路径
虽然我们也可以使用alias手段,把这一串命令缩短成一个词,以方便我们直接使用voice2srt 目标音频文件路径 的命令完成目标,但还是要基于命令行,多有不便。
主要是,我们也不需要修改其他参数(基本按照默认即可,热词已经在讯飞官网配好了)。
那么这种纯粹基于文件的操作,在 mac 平台上最好的办法是写一个automator脚本:
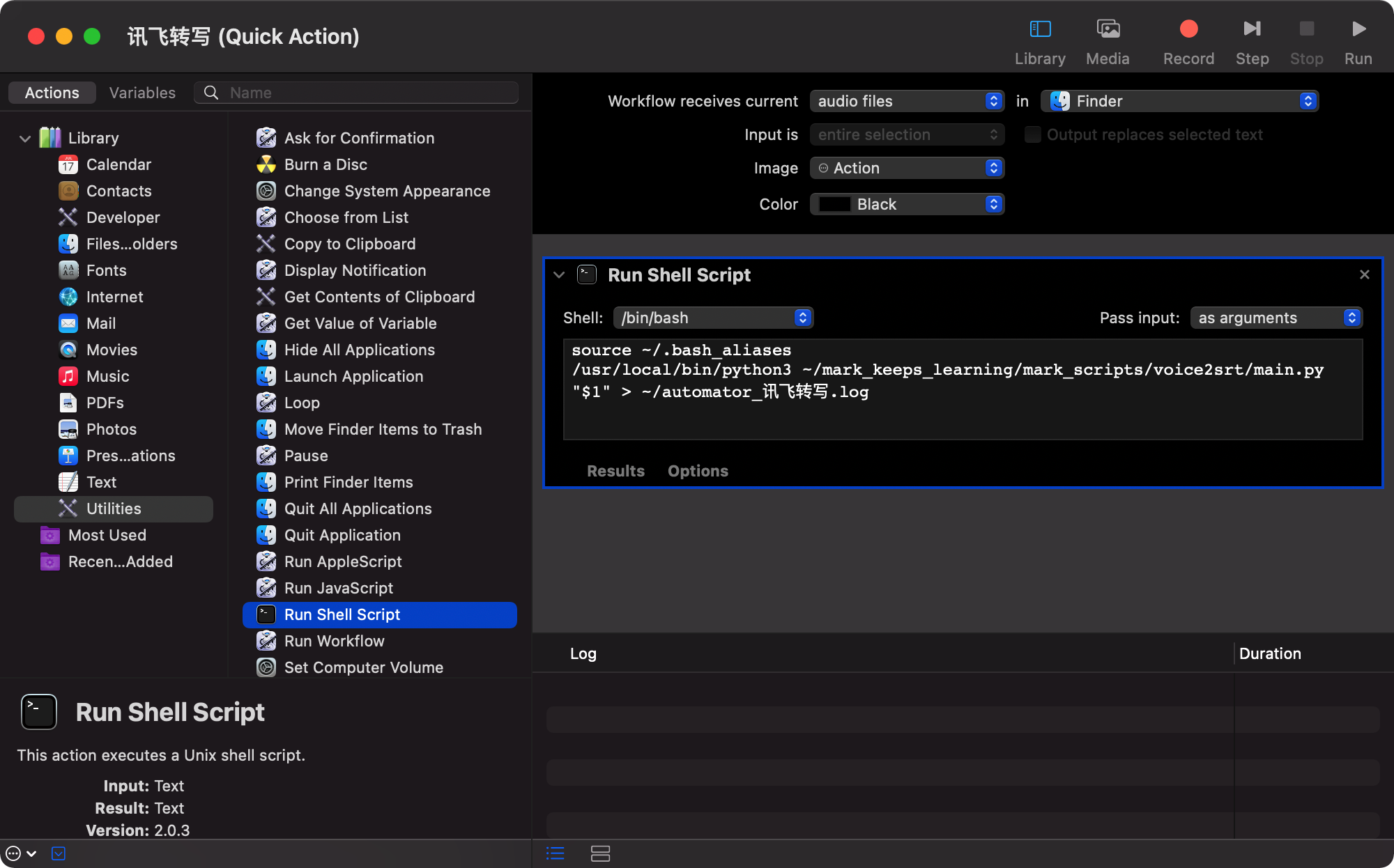
这样我们就可以直接在 finder 里面右键我们的音频文件,然后在快捷菜单中找到我们的 automator 脚本选项,鼠标一点就自动转成了,非常方便!
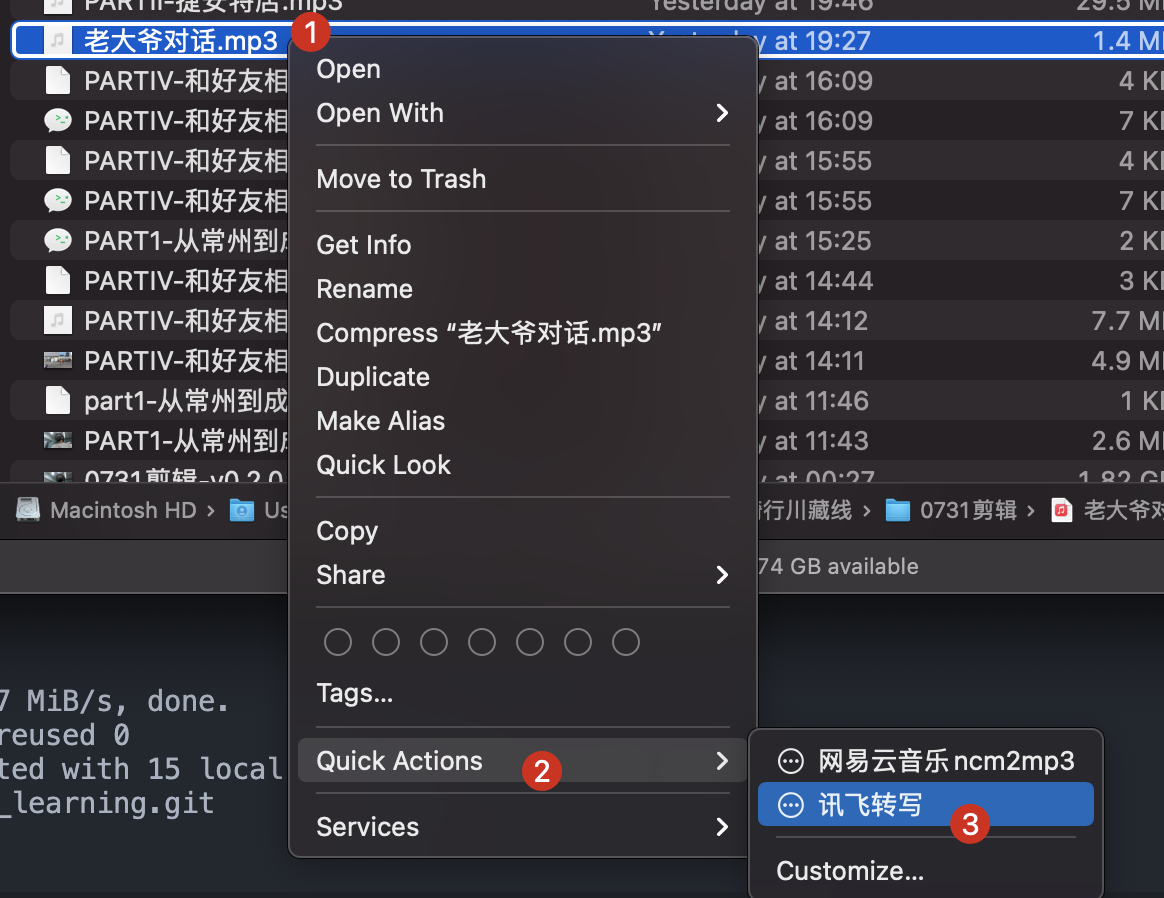
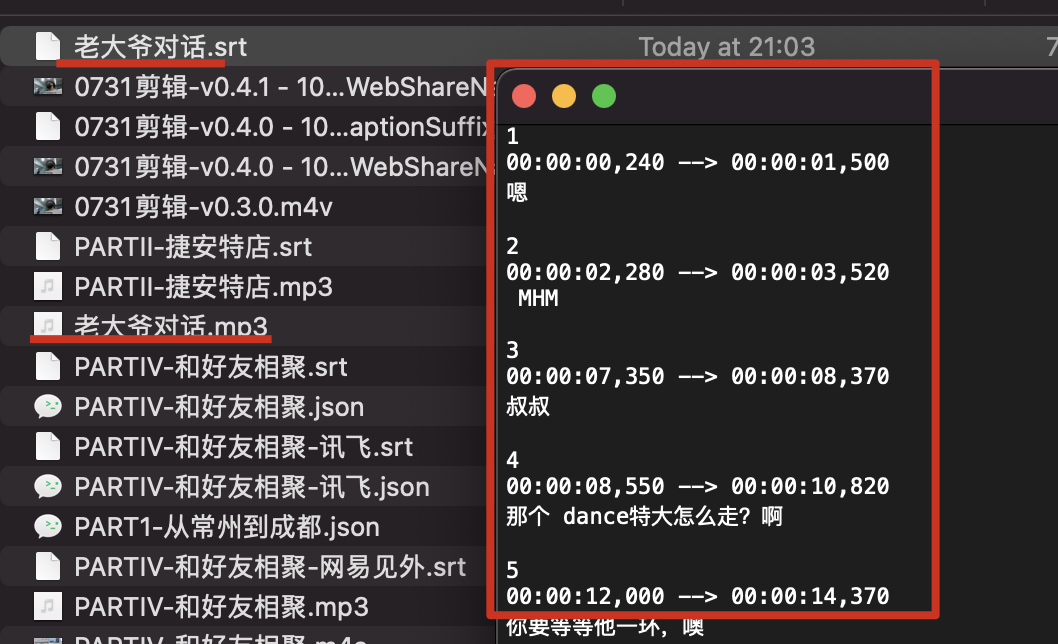
十秒钟之后,就自动在当前文件夹内生成一个讯飞转写后的字幕文件了,非常方便:
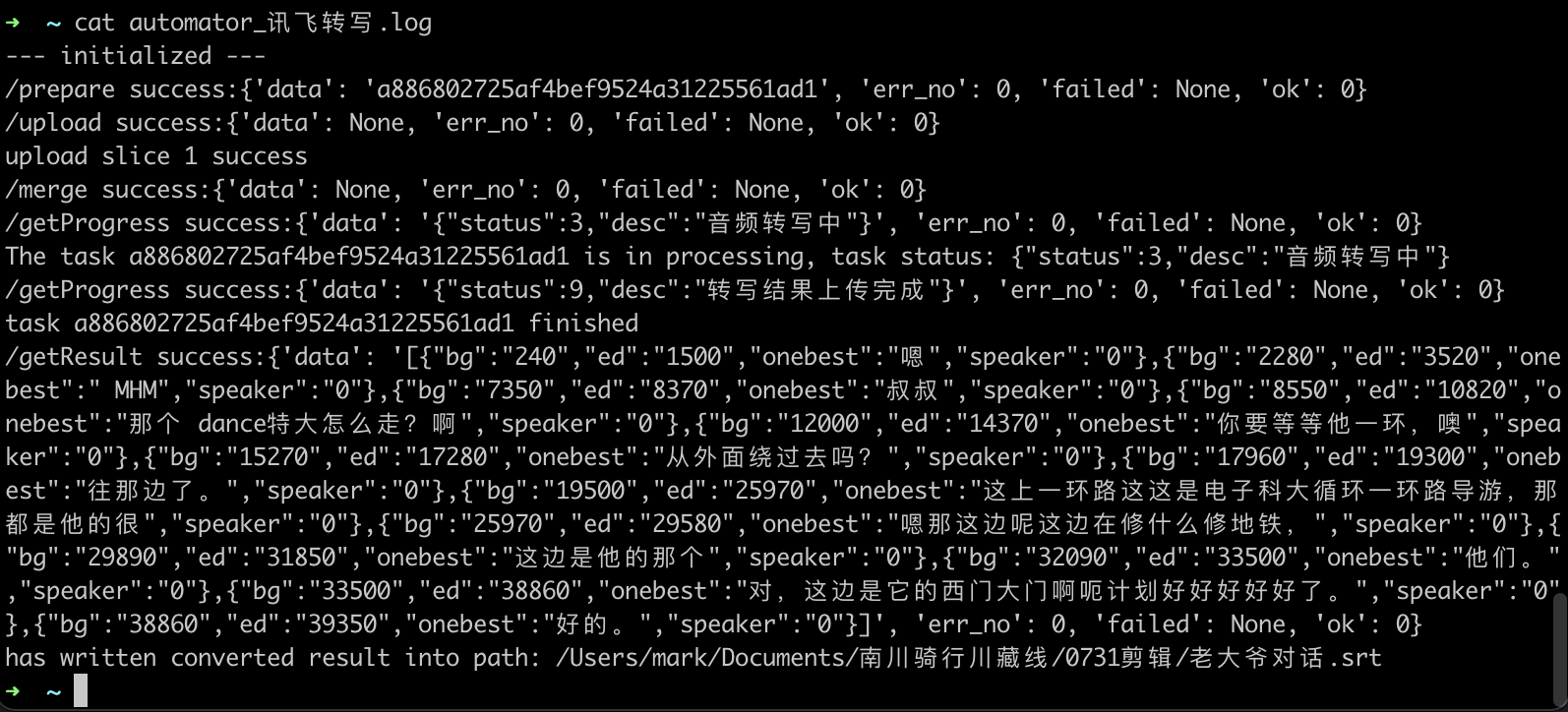
并且我将标准输出重定位到了根目录的 log 文件,这样就可以在程序出错时复查:
Automator 是一个很有用的工具,我也对它越来越感兴趣了,比如说还写了一个网易云音乐 ncm 转 mp3 的快捷操作,这样右键一个 ncm 文件,就能转成 mp3 了,非常方便。
但愿本文对你有帮助~